

The student learning flow is the moment an LMS stops being an admin tool and becomes the thing learners actually use. Everything earlier in this series — the multi-tenant data model, the media pipeline, the assessment engine, the events backbone, and the instructor workspace from Part 12 — exists so that a student can do five things well: discover a course, enrol, work through its lessons, be graded, and walk away with proof they finished. Part 13 builds that student learning flow end to end, server-rendered in Spring Boot and Thymeleaf, and it does it almost entirely by composing machinery the previous parts already built and verified.
That reuse is the story of this part. The catalogue is the published side of Part 12’s authoring. Enrolment is Part 2’s idempotent, seat-capped operation. The assessment is Part 4’s deterministic auto-grader. Progress is modeled with the same idempotent-fact discipline that has run through enrolment, submission, events, and billing. By the end, a learner signs in, enrols in a course, ticks off lessons, takes an auto-graded quiz, and earns a completion certificate — and the new code to make that happen is small, because the guarantees underneath it are already load-bearing.
Where Part 13 sits in the series
This is the third instalment of the “working platform” arc that turns the reference backend into something you can run and operate. Parts 11–14 build out the three role workspaces:
| Part | Role | What becomes real |
|---|---|---|
| 11 | All roles | Login, RBAC, tenant-from-identity, role dashboards |
| 12 | Instructor | Author courses & lessons, draft→publish, cohort rosters |
| 13 | Student | Catalogue → enrol → course player → auto-graded assessment → progress & certificate |
| 14 | Admin | Console depth: billing view, reports, deeper user management |
The instructor in Part 12 published courses with ordered lessons. Part 13 is the other side of that coin: the student consumes exactly what the instructor authored. The two roles share the same data, viewed from opposite ends.

The reuse dividend: what we don’t have to build
Before any new code, it’s worth naming what the student flow gets for free, because it explains why this part is more assembly than invention:
- Authentication, RBAC, and tenant isolation (Part 11). The student signs in;
/learn/**is gated toROLE_STUDENT; the tenant is pinned from the session before any controller runs. The student controller never passes a tenant id, and a student can’t reach instructor or admin routes. - Idempotent, seat-capped enrolment (Part 2). The
EnrollmentService.enrolloperation is find-or-create with a@Versionoptimistic lock, so a double-clicked “Enrol” never double-enrols or oversells a cohort. - Course content (Part 12). Courses and their ordered lessons already exist, authored through the instructor workspace and published into the catalogue.
- Deterministic auto-grading and exactly-once submission (Part 4). The pure
AutoGraderscores single-choice, multiple-choice (proportional partial credit), and short-text questions;Attempt.submitis one-way and idempotent.
What’s genuinely new in Part 13 is small: a way to find published courses, a way to enrol by course rather than by cohort, a lightweight Learning & Progress context that records lesson completions, and the student-facing UI that stitches it together.
The catalogue: published courses only
A learner should see courses that are ready, not half-authored drafts. Part 12 made publishing a deliberate, guarded transition; Part 13 honours it by querying only published courses for the catalogue:
public interface CourseRepository extends JpaRepository<Course, UUID> {
/** Part 13: the published catalogue a learner can browse — drafts stay hidden. Tenant-scoped. */
List<Course> findByPublishedTrueOrderByTitleAsc();
}As with every query in this system, the method names the business intent (findByPublishedTrue) and Spring Data writes the SQL, while Hibernate’s @TenantId silently adds the tenant filter underneath. So the catalogue shows this organisation’s published courses, ordered by title, and nothing else. A draft an instructor is still writing is invisible to students until the moment they publish it — the visibility rule is the database query, not a checkbox someone has to remember to honour in the UI.
On the catalogue page, each course shows its lesson count and either an Enrol button or, if the learner is already in it, a Continue link. That “already enrolled?” check is computed once per request by resolving the learner’s enrolments to a set of course ids — the same join the instructor’s roster used in Part 12, run in the other direction:
private Set<UUID> enrolledCourseIds(UUID learnerId) {
Set<UUID> ids = new HashSet<>();
for (Enrollment e : enrollment.enrollmentsForLearner(learnerId)) {
ids.add(enrollment.cohort(e.cohortId()).courseId());
}
return ids;
}An enrolment points at a cohort by id; the cohort points at a course by id. The controller walks that chain explicitly — the by-id, cross-context discipline from earlier parts — rather than traversing a JPA object graph, so the Enrollment context never has to import the Catalog context’s entities. The same helper, surfaced as a set membership test, drives the catalogue’s Enrol-vs-Continue toggle and the de-duplication on the “My learning” page below.
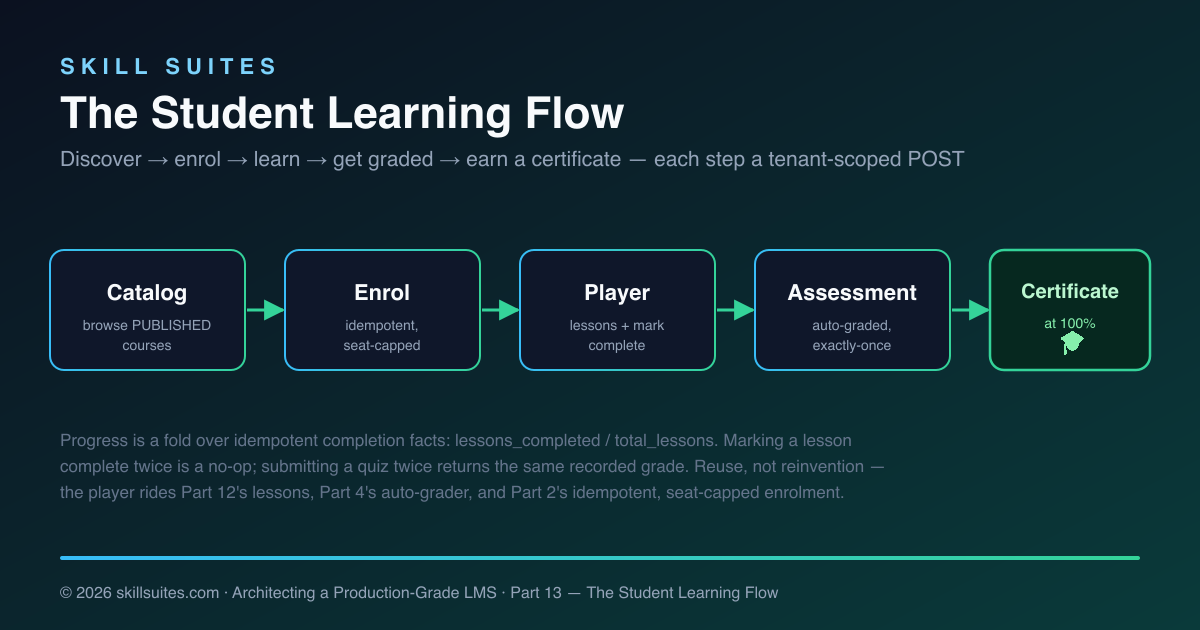
Enrolment: by course, idempotently
Here a small modelling decision matters. Internally, a learner doesn’t enrol in a course — they take a seat in a cohort (a class, a run of the course), which is what carries the capacity and the seat invariant from Part 2. But a student browsing the catalogue thinks in courses, not cohorts. So the student flow needs to bridge the two, and the bridge lives in the enrolment service:
@Transactional
public Enrollment enrollInCourse(UUID courseId, UUID learnerId) {
Cohort target = cohorts.findByCourseId(courseId).stream()
.filter(c -> c.seatsRemaining() > 0)
.findFirst()
.orElseGet(() -> cohorts.save(Cohort.create(courseId, DEFAULT_COHORT_CAPACITY)));
return enroll(target.id(), learnerId);
}The method resolves a cohort for the course — the first one with a seat free, or a fresh default cohort if the course has none yet — and then delegates to the existing enroll(cohortId, learnerId). That delegation is the important part: enroll is the idempotent, version-guarded operation built and tested back in Part 2. A student who double-clicks “Enrol”, or refreshes the confirmation, resolves to the same enrolment rather than taking two seats. We didn’t re-implement enrolment for the student UI; we put a course-shaped front door on the cohort-shaped operation that was already correct.
After enrolling, the controller redirects straight into the course player — Post/Redirect/Get again, so the enrol action happens once and a refresh just re-reads the course.
A new context: Learning & Progress
The one substantially new piece of domain in Part 13 is how we track what a learner has done. The series reserved a learning package early on for exactly this; Part 13 fills it in with a single entity and a thin service.
The entity is a LessonCompletion — the bare fact that a learner finished one lesson:
@Entity
@Table(name = "lesson_completions")
public class LessonCompletion {
@Id private UUID id;
@TenantId
@Column(name = "tenant_id", nullable = false, updatable = false)
private UUID tenantId;
@Column(name = "learner_id", nullable = false, updatable = false) private UUID learnerId;
@Column(name = "course_id", nullable = false, updatable = false) private UUID courseId;
@Column(name = "lesson_id", nullable = false, updatable = false) private UUID lessonId;
@Column(name = "completed_at", nullable = false) private Instant completedAt;
// factory + accessors omitted
}And the migration mirrors every other table in the system — tenant_id, an index, Row-Level Security — plus the one constraint that makes the whole design work:
create table lesson_completions (
id uuid primary key,
tenant_id uuid not null references organizations (id),
learner_id uuid not null references app_users (id),
course_id uuid not null references courses (id),
lesson_id uuid not null references lessons (id),
completed_at timestamptz not null,
constraint uq_completion_learner_lesson unique (tenant_id, learner_id, lesson_id)
);The war story: the progress counter that always drifts
There is an obvious way to track progress, and it’s wrong. The obvious way is to keep an integer — lessons_completed — on an enrolment or progress row, and increment it each time a learner finishes a lesson. It’s one column, one UPDATE, and it’s the design that quietly rots every LMS that ships it.
The problem is that a counter is a derived value pretending to be a fact, and the moment your delivery isn’t perfectly exactly-once, it drifts. A learner double-clicks “mark complete” and the counter reads 13 of 12. A retried request after a dropped response increments twice. A lesson is deleted and now the counter is higher than the lesson count. A re-sync from a mobile client (the offline story from Part 9) replays completions and inflates everything. You end up writing reconciliation jobs to repair a number you never needed to store.
The fix is to store the facts and derive the number. Each LessonCompletion row is an idempotent fact: “this learner completed this lesson.” The unique constraint on (tenant_id, learner_id, lesson_id) means recording the same completion twice is a no-op — the second write resolves to the existing row. Progress is then just a fold over those facts:
@Transactional
public void markComplete(UUID learnerId, UUID courseId, UUID lessonId) {
if (completions.existsByLearnerIdAndLessonId(learnerId, lessonId)) {
return; // already done — no double counting
}
completions.save(LessonCompletion.of(learnerId, courseId, lessonId, Instant.now(clock)));
}
@Transactional(readOnly = true)
public long completedCount(UUID learnerId, UUID courseId) {
return completions.countByLearnerIdAndCourseId(learnerId, courseId);
}Now drift is structurally impossible. “75% complete” is completedCount / lessonCount, computed on read from rows that can’t be double-counted, so a double-click, a retry, or an offline re-sync all converge to the same answer. This is the same idempotent-write discipline the series used for enrolment seats, exam submission, the outbox events pipeline, and billing webhooks — now applied to progress. The lesson generalises past LMSs: when a number can be derived from idempotent facts, derive it; don’t maintain it. Counters you maintain are counters you reconcile.
Maintained counter (lessons_completed) |
Derived fold (count of facts) | |
|---|---|---|
| Double-click “complete” | Over-counts (13 of 12) | No-op — unique row already exists |
| Retried request after dropped response | Increments twice | Idempotent — same fact |
| Offline re-sync replays completions | Inflates the total | Converges — set union of facts |
| A lesson is deleted | Counter now exceeds lesson count | Self-corrects on next read |
| Audit “which lessons did they do?” | Impossible — only a number survived | The rows are the audit trail |
| Repair when it drifts | Write a reconciliation job | There is nothing to repair |

“My learning”, deduplicated by course
A learner can hold seats in more than one cohort of the same course (they re-took it with a new class, say), but “My learning” should list each course once, with one progress figure. So the controller folds enrolments into a course-keyed map, computing progress per course as it goes:
Map<UUID, MyCourseRow> byCourse = new LinkedHashMap<>();
for (Enrollment e : enrollment.enrollmentsForLearner(learnerId)) {
UUID courseId = enrollment.cohort(e.cohortId()).courseId();
if (byCourse.containsKey(courseId)) continue; // one row per course
catalog.findCourse(courseId).ifPresent(course -> {
long total = catalog.lessonCount(courseId);
long done = learning.completedCount(learnerId, courseId);
int pct = total == 0 ? 0 : (int) Math.round(done * 100.0 / total);
byCourse.put(courseId, new MyCourseRow(courseId, course.title(), done, total, pct,
learning.isCourseComplete(learnerId, courseId, total)));
});
}The same rows back the student dashboard (which also surfaces a “continue learning” nudge — the first course that isn’t finished) and the progress page. One small helper, three screens, each consistent with the others because they’re all reading the same derived facts.
The course player
The player is where the learner spends their time. It shows the course’s lessons in author-defined order, each with its content and a Mark complete button, a live progress bar, the course’s assessments, and — once every lesson is done — a completion certificate.
The controller assembles a view model rather than handing entities to the template: it loads the lessons (Part 12’s ordered query), asks the learning service which lesson ids this learner has completed, and zips them together into a list of rows that know their own completed state:
Set<UUID> completed = learning.completedLessonIds(learnerId, courseId);
List<LessonView> lessons = new ArrayList<>();
for (Lesson l : catalog.lessons(courseId)) {
lessons.add(new LessonView(l.id(), l.position(), l.title(), l.body(), completed.contains(l.id())));
}Marking a lesson complete is a plain HTML form POST to /learn/courses/{courseId}/lessons/{lessonId}/complete, which calls markComplete and redirects back to the player (anchored to the lesson). Because markComplete is idempotent and the route uses Post/Redirect/Get, a refresh or a second click is harmless — the defining property we want for a button a learner will mash.
The certificate is not a stored artefact; it’s a derived state, exactly like progress. When completedCount >= lessonCount (and there’s at least one lesson), the player renders a “Course complete — certificate earned” banner. There’s nothing to issue or revoke; completion is a fact about the completion rows, computed on read.
The assessment: graded exactly once
Lessons teach; assessments verify. Part 13 wires the student into the assessment engine built in Part 4, and the wiring is careful in two specific ways.
Starting an attempt resumes, it doesn’t restart. When the learner opens a quiz, the controller calls startAttempt(assessmentId, learnerId). That method (from Part 4) returns an in-progress attempt if one exists, and only creates a new one — subject to the attempts policy — if every prior attempt is graded. So a learner who navigates away and comes back, or opens the quiz on a second device, resumes the same attempt rather than burning another from their budget. The attempt id is carried in a hidden form field, so the submit targets that exact attempt.
The answer key never reaches the browser. The controller maps each question to a view model that carries the prompt, the type, the points, and the options — but not the answerKey. Grading happens server-side; the client is never told which option is correct, so it can’t be scraped from the page source.
for (Question q : assessment.questions(assessmentId)) {
questions.add(new QuestionView(q.id(), q.type().name(), q.prompt(), q.points(), q.options()));
}The quiz form renders each question by type: radio buttons for single-choice, checkboxes for multiple-choice, a text input for short-text. Each input is named q_<questionId> and its value is the option’s index (or the typed text). On submit, the controller collects the answers into the Map<UUID, Set<String>> shape the grader expects and hands it to the existing submitAttempt:
Map<UUID, Set<String>> answers = new HashMap<>();
for (Question q : assessment.questions(assessmentId)) {
String[] vals = request.getParameterValues("q_" + q.id());
if (vals != null) answers.put(q.id(), new HashSet<>(Arrays.asList(vals)));
}
GradedResult result = assessment.submitAttempt(attemptId, answers); // idempotentBecause submitAttempt is exactly-once (from Part 4), a double-submitted quiz returns the already-recorded grade instead of regrading — the learner can’t accidentally overwrite a result by hitting back-and-submit. The result page shows the score, the percentage, and a pass/fail badge, with a deterministic, server-side grade the learner could never have forged from the page.
Why answers are option indices, not labels
A subtle but important choice: each choice answer is submitted as the option’s index (“0”, “1”, “2”), not its text. That keeps the contract between the form and the grader stable and language-neutral. The AutoGrader stores its answer key as the same indices, so grading is a set comparison of positions, immune to a re-worded option, a trailing space, or a future translation of the label. For short-text questions the value is the typed string, which the grader normalises (trim, lower-case, collapse whitespace) before matching — so “@Version” and ” @version ” both score. Single-choice is all-or-nothing; multiple-choice awards proportional partial credit, floored at zero, so guessing every box doesn’t beat answering carefully.
The attempts policy is enforced server-side too: the assessment’s maxAttempts is checked against the number of graded attempts the learner already has, counted from the database, not the request. An in-progress attempt is resumed rather than counted, so refreshing the quiz never burns the budget; only a genuinely new, post-grade start consumes one. The client cannot bypass the limit because the count it would need to forge lives on the server.
Progress & certificates
The final screen is the learner’s progress across every enrolled course: a table of progress bars and, for any course at 100%, a “Certificate earned” badge. It’s built from the same myCourseRows helper the dashboard and “My learning” pages use — each row computes done / total on the fly. Because the numbers are derived from idempotent facts, this page is always internally consistent: the percentage, the lesson counts, and the certificate state can never disagree, because they’re three views of the same underlying rows.
How it composes: one request, many parts
Opening the course player is a good illustration of how little Part 13 actually adds. A single GET to /learn/courses/{id} touches four bounded contexts, three of which were built in earlier parts:
- Catalog supplies the course and its ordered lessons (Part 12).
- Learning supplies the set of completed lesson ids (Part 13, new).
- Assessment supplies the course’s quizzes and the learner’s best score (Part 4).
- Enrollment and Identity underpin who the learner is and what they’re enrolled in (Parts 2 and 11).
The controller is the only place these meet, and it meets them through their public service APIs — never by reaching into another context’s internals, a boundary the ArchUnit test enforces on every build. Each context stays a thing you could one day extract; the student page is just a composition of their public surfaces.
Walking the full request makes the layering concrete. A GET to /learn/courses/{id} runs:
- Spring Security confirms the session and that the principal holds
ROLE_STUDENT; a wrong-role or anonymous request is stopped at the edge with a 403 or a redirect to/login. - The tenant filter pins the current tenant from the authenticated principal — before any session opens, so every query below is filtered automatically.
- The controller reads
principal.userId()as the learner id and calls the four contexts’ services to build the view model. - Hibernate applies the
@TenantIdfilter to each query using the pinned tenant; PostgreSQL Row-Level Security stands behind it as a second wall. - Thymeleaf renders
student/player.htmlserver-side, splicing in the shared role-aware shell fragment, and returns finished HTML.
The only code written for Part 13 in that chain is step 3 — a few dozen lines of view-model assembly. Authentication, authorisation, tenant isolation, the SQL filter, and the rendering shell are all inherited. That is what “build the boring foundations first” buys you: by the time you reach the feature users care about, it’s a thin composition over guarantees that are already true.
The learner experience works without JavaScript
Every interaction in the student flow — enrolling, marking a lesson complete, answering and submitting a quiz — is a plain HTML <form> posting to a controller route. There is no client framework, no fetch call, no hydration step. That is a deliberate accessibility and resilience choice, and it matters more for an LMS than for most software, for the reasons Part 9 set out: learners include people on assistive technology, on locked-down institutional machines, on flaky connections, and on devices where heavy JavaScript simply fails.
A server-rendered, form-based flow degrades gracefully to all of them. Radio buttons and checkboxes are native, keyboard-operable controls that screen readers announce correctly without any ARIA gymnastics. The quiz is a real form that submits even if scripting is disabled. The progress bar is server-computed markup, not a client animation that might never run. None of this precludes progressive enhancement later — a sprinkle of JavaScript could make the quiz feel snappier — but the baseline is a flow that works for everyone, and Post/Redirect/Get keeps it safe to refresh. For a platform whose entire purpose is access to learning, “works without JavaScript” is not a constraint to apologise for; it’s the floor.
Code → file map
| Concern | File |
|---|---|
| The published-catalogue query | catalog/internal/CourseRepository.java, catalog/CatalogService.java |
| Enrol by course (find-or-create cohort → idempotent enrol) | enrollment/EnrollmentService.java |
| The lesson-completion fact (tenant-scoped, unique) | learning/domain/LessonCompletion.java |
| Progress as a fold over facts | learning/LearningService.java |
| Render the quiz / best result, without leaking the key | assessment/AssessmentService.java |
| The student UI routes (catalog, enrol, player, quiz, progress) | web/ui/StudentController.java |
| Templates: catalog, courses, player, quiz, result, progress, dashboard | templates/student/*.html |
| The completions table + RLS | db/migration/V9__learning.sql |
| Seeded published courses, lessons, and a quiz | config/DataSeeder.java |
Seeded for a real demo
A flow you can’t try is just a diagram. So Part 13 expands the demo seed (the idempotent DataSeeder that runs on first boot) into something a learner can actually use end to end. The Acme University tenant now ships four published courses — Multi-Tenant SaaS Architecture, Streaming & the Outbox Pattern, Production Resilience & SRE, and Accessible Web Apps — each authored as an ordered set of lessons, each with a cohort ready to take enrolments. The seeded student, Maria, is already enrolled in two of them, so “My learning” and the dashboard show real progress the instant you log in, and the catalogue offers the other two with a live Enrol button.
One course carries an auto-graded “Multi-Tenancy Knowledge Check” — a single-choice question, a multiple-choice question with partial credit, and a short-text answer — so the assessment path ends in a genuine, deterministic grade rather than a stub. The seeding is careful to respect the architecture it teaches: it sets the tenant context before any tenant-scoped write (the session-boundary rule from earlier parts), publishes through the same guarded Course.publish() transition the instructor uses, and authors lessons through the same CatalogService.addLesson. The demo isn’t special-cased data injected behind the model’s back; it’s the model’s own public operations, run once at startup.
Run it yourself
The seeded Acme University tenant now ships published courses (each with lessons) and an auto-graded quiz, so the whole flow works on first boot:
git clone https://github.com/muasif80/tutorial-lms-platform.git
cd tutorial-lms-platform
git checkout part-13
docker compose up -d --build
open http://localhost:8080/login # sign in as [email protected] / scholrThe seeded student (Maria) is already enrolled in two courses, so the dashboard shows real progress immediately. Things to try:
- Enrol. Open the Catalog, pick a course you’re not in, and click Enrol — you land straight in the course player. Click it twice; you still hold exactly one seat.
- Learn. In the player, Mark complete on a few lessons and watch the progress bar move. Complete them all and the completion certificate banner appears.
- Get graded. Take the “Multi-Tenancy Knowledge Check” on the first course. Answer, submit, and see an instant deterministic grade. Submit the same attempt again — you get the same score back, not a new one.
- Track. Open Progress & Certificates for the whole-account view.
How we know it works
As with every part, Part 13 isn’t done until mvn verify is green in CI. The new learning context joins the build with the rest of the persistence and architecture tests; the ArchUnit modularity checks confirm that the new student controller composes contexts only through their public APIs and that the new learning module doesn’t entangle itself in a dependency cycle. Tenant isolation, idempotent enrolment, and deterministic grading are all already proven by the suites from Parts 2 and 4 — Part 13 rides those guarantees rather than re-establishing them. And the flow is verified the way a learner experiences it: deployed live, signed in as the seeded student, enrol → complete lessons → take the quiz → see the certificate, every screenshot from the running system.
What a production version would add
This is an educational reference, and it’s honest about its edges. The student flow is complete and correct, but a platform serving real learners and real money would extend it in a few predictable directions — each of which slots onto the seams this part establishes rather than rewriting them:
- Richer lesson content. The lesson body here is text; a real player renders typed blocks — video (the signed-CDN pipeline from Part 3 is already built), embedded quizzes, slides, and code sandboxes. The
Lessonaggregate is the seam where those blocks attach; the player, progress model, and completion logic don’t change. - Sequencing and prerequisites. Today every lesson is open; a real course might gate lesson n+1 on completing lesson n, or require a passing assessment to unlock the next module. That’s a rule on top of the completion facts we already record — a read, not a new store.
- Time-on-task and resume position. The offline-sync engine from Part 9 already models a last-write-wins position cursor; wiring it into the player gives “resume where you left off” across devices.
- Verifiable certificates. The completion state is derived and correct; a production system would mint a signed, verifiable certificate artefact (a PDF with a tamper-evident verification URL) when that state first flips to complete — issuing off the same boundary the banner reads.
- Engagement signals. Streaks, reminders, and recommendations (the discovery engine from Part 6) all feed off the completion and enrolment facts this part emits.
None of these change the spine. They’re additive precisely because the spine — idempotent enrolment, derived progress, server-side grading, hard tenant isolation — was built to be extended, not patched.
What Part 13 unlocks
With instructors authoring (Part 12) and students learning (Part 13), the platform now generates the data an organisation wants to see in aggregate — which is exactly Part 14’s subject. The admin console will roll up what these two flows produce: how many courses are published, how full the cohorts are, how learners are progressing, and what’s being billed. Every number on the admin’s dashboard is a sum over the facts the instructor and student workspaces create. The roles compose into a platform, and the admin is where you finally see the whole thing at once.
Key takeaways
- Compose, don’t reinvent. The student flow is mostly assembly: enrolment is Part 2’s idempotent operation, grading is Part 4’s auto-grader, content is Part 12’s lessons, isolation is Part 11’s. New code is small because the foundations are solid.
- The catalogue is a query, not a flag honoured by the UI. Only published courses are returned, so a draft is invisible to learners by construction.
- Enrol by course, delegate to cohort. A course-shaped front door on the cohort-shaped, seat-capped, idempotent enrolment keeps the student UI simple and correct.
- Store facts, derive numbers. Progress is a fold over idempotent
LessonCompletionrows, not a counter — so it can never drift, even under double-clicks or offline re-sync. The certificate is derived the same way. - Grade server-side, exactly once. The answer key never reaches the browser; submission is idempotent, so a double-submit returns the same recorded grade.
Frequently asked questions
Why model progress as completion facts instead of a percentage or a counter?
Because a counter is a derived value pretending to be a fact, and it drifts the moment delivery isn’t perfectly exactly-once — a double-click, a retry, or an offline re-sync over-counts it. Storing one idempotent LessonCompletion row per lesson, with a unique constraint on (tenant, learner, lesson), makes recording the same completion twice a no-op. Progress is then completed / total computed on read, which can never disagree with itself and never needs a reconciliation job.
How does a student enrol in a course when the seat invariant is on cohorts?
The student picks a course; enrollInCourse resolves a cohort for it — the first with a free seat, or a new default cohort — and then delegates to the existing idempotent enroll(cohortId, learnerId) from Part 2. So the student UI thinks in courses while the seat cap and optimistic-lock guarantees still apply at the cohort level, and a repeated click never double-enrols.
Can a student see or game the assessment answers?
No. The controller maps each question to a view model that omits the answer key, so the correct options are never sent to the browser. Grading runs server-side in the deterministic AutoGrader from Part 4, and submission is exactly-once: a double-submit returns the already-recorded grade rather than regrading, so a learner can’t overwrite a result either.
What happens if a learner clicks “mark complete” twice, or refreshes?
Nothing bad. markComplete first checks whether the completion already exists and returns early if so, and the route uses Post/Redirect/Get, so a refresh re-issues a harmless GET rather than re-posting. The unique constraint is the final backstop at the database level.
Is the completion certificate a stored document?
No — it’s a derived state, like progress. When the count of completed lessons reaches the course’s lesson count, the player and progress pages render a “certificate earned” badge. There’s nothing to issue, store, or revoke; completion is computed from the completion rows on read, so it’s always consistent with actual progress.
Why server-rendered Thymeleaf for the learner experience?
For this series the goal is one deployable that demonstrates the architecture honestly, and a server-rendered flow works without JavaScript — an accessibility property that matters for an LMS, as Part 9 argued. Every action is a plain HTML form posting to a controller route. A production team could layer a richer client on the same REST API, but the server-rendered version is the runnable baseline that proves the backend works end to end.
