

Across this series we have built Scholr’s spine — the domain and modular monolith in Part 1, the multi-tenant data model in Part 2, and video at scale in Part 3. Now we reach the two features learners actually feel: the exam they take and the live class they sit in. Both are deceptively hard, and they fail in opposite directions. An assessment that grades wrong is a correctness failure — quiet, corrosive, and disputed one angry email at a time. A live class that can’t hold its audience is a scale failure — loud, instantaneous, and witnessed by everyone at once. This part builds both: a deterministic auto-grading engine with exactly-once submission, and a WebSocket architecture that survives a 50,000-person live class.
The crisis that frames it is one Scholr lived through twice in a single week. On Monday, a learner submitted a 40-question final, lost their connection on the last click, hit submit again — and was billed two attempts, the second a zero, because the retry landed after the deadline. On Thursday, Scholr’s most popular instructor went live to a launch cohort; at roughly forty thousand concurrent viewers the chat froze, presence counts went backwards, and a third of the room got disconnected and couldn’t rejoin. One bug was about correctness under retry; the other about real-time under load. They share a root lesson: at scale, the naive version of “submit a form” and “broadcast a message” both break, and they break publicly.
The assessment domain: what must be modeled before any code grades anything
Before a single score is computed, the domain has to be honest about what a real exam is. It is not a list of questions; it is a policy wrapped around a question bank. Scholr’s model has three aggregates, each tenant-scoped exactly like everything from Part 2.
- Assessment — the quiz or exam attached to a course. It owns the rules: how many attempts a learner may take, and how long a single attempt may run. Crucially, these are server-side facts, not client hints.
- Question — one gradable item in the bank: a type, a prompt, the points it is worth, its option labels, and — the part that never leaves the server — its answer key. A question references its assessment by id, never by a JPA association, so the bank can be paged without dragging the whole exam into memory (the Part 2 reference-by-id rule).
- Attempt — one learner’s run at an assessment, and the aggregate where correctness meets concurrency. It carries a
@Versionoptimistic lock and a one-way lifecycle, which is what makes exactly-once submission possible.
A real product supports more question types than we will grade here (matching, ordering, numeric-with-tolerance, code execution), and a serious exam engine adds randomization from a larger pool, per-question time, and partial-credit rubrics. But the three types Scholr ships — single choice, multiple choice, short text — are exactly the ones a machine can grade deterministically, and that boundary is the whole point of the next section.

One modeling choice deserves emphasis because it shapes both fairness and integrity: the question bank is larger than any single attempt. An assessment of “ten questions” is really a pool of, say, eighty, from which each learner is served a randomized ten, with the option order shuffled too. This does three things at once. It makes casual cheating pointless — two learners side by side don’t share an answer key. It lets the same assessment be retaken without memorization, because attempt two draws a different ten. And it keeps the grader honest: because the answer key travels with each question, not with the assessment, a randomized selection grades exactly as correctly as a fixed one. The selection is a server-side decision recorded on the attempt, never a client choice — otherwise a motivated learner simply asks the API for the easy questions. Scholr’s model keeps the key on the question and the selection on the server, so randomization is a fairness feature rather than a new attack surface.
A deterministic grading engine: arithmetic, not judgment
The single most important decision in an assessment engine is also the one teams get wrong most often: a machine should grade only what it can grade by arithmetic, and it should never fabricate a number for something that requires judgment. This is the same boundary our production-LLM playbook draws — a model is wonderful at suggesting and summarizing, and dangerous the moment its guess is treated as an authoritative score. So Scholr’s grader is a pure function: no Spring, no database, no clock, no randomness. Same inputs, same score, every time, on every node.
That purity is not academic. It is what makes a grade defensible. When a learner disputes a result, you do not re-run a stochastic model and hope; you point at a function whose output is reproducible and whose rules are written down. Here is the heart of it — three rules, one per supported type:
int scoreOne(Question q, Set<String> given) {
return switch (q.type()) {
case SINGLE_CHOICE -> scoreSingleChoice(q, given); // all-or-nothing
case MULTIPLE_CHOICE -> scoreMultipleChoice(q, given); // proportional partial credit
case SHORT_TEXT -> scoreShortText(q, given); // normalized exact match
};
}Single choice is all-or-nothing. Short text matches after normalization (trim, lower-case, collapse internal whitespace) so a learner never loses points for typing " Paris " instead of "Paris" — but it is deterministic string equality against an accepted set, never fuzzy “AI” matching, precisely so it stays explainable. Multiple choice is where most engines cop out with an all-or-nothing cliff; Scholr gives proportional partial credit: each correct option selected earns a share of the points, each wrong option selected forfeits a share, floored at zero so a guess-everything strategy nets nothing and a score can never go negative.
private int scoreMultipleChoice(Question q, Set<String> given) {
Set<String> key = q.answerKey();
int wrongOptions = q.options().size() - key.size();
long correctSelected = given.stream().filter(key::contains).count();
long wrongSelected = given.stream().filter(o -> !key.contains(o)).count();
double creditPerCorrect = (double) q.points() / key.size();
double penaltyPerWrong = wrongOptions == 0 ? 0.0 : (double) q.points() / wrongOptions;
double raw = correctSelected * creditPerCorrect - wrongSelected * penaltyPerWrong;
return Math.min((int) Math.round(Math.max(0.0, raw)), q.points()); // never <0, never >max
}The engine is exhaustively unit-tested without a running application — because it is pure, the tests are pure too: feed it questions and answers, assert a number. That is the dividend of keeping judgment out of the grader.
| Grading style | What it rewards | Determinism | Disputability |
|---|---|---|---|
| Deterministic rules (our choice) | Exactly the answer key, by arithmetic | Total — reproducible on any node | Settled by re-running a pure function |
| LLM “auto-grade” of objective items | Whatever the model felt | None — varies by run/temperature | Unwinnable; no ground truth |
| Human grading | Genuine judgment (essays) | N/A — that’s the point | Appealable to a rubric |
The rule that falls out: deterministic rules for objective items, humans (or a clearly-labeled judgment model as a separate step) for the subjective ones. The grader never blurs the line.
Idempotent, exactly-once submission: the bug that double-charged a learner
Now Monday’s incident. A submission is a write that must happen exactly once even though the network guarantees nothing of the sort: requests get retried, users double-click, mobile clients resend on a flaky connection, and a queue will happily redeliver a message it isn’t sure you processed. The naive handler — “grade the answers, insert a result row” — turns every one of those into a duplicate grade.
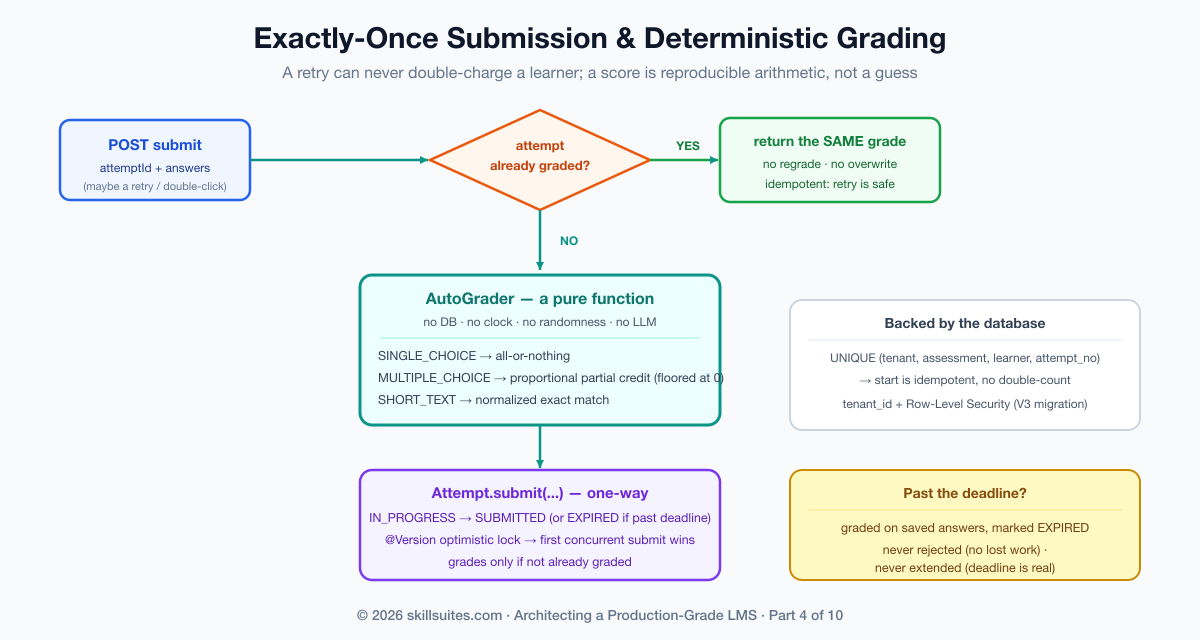
Scholr solves it with the same discipline Part 2 used for enrollment: make the write idempotent at the aggregate, and back it with a database constraint. The Attempt has a one-way submit that grades only if not already graded:
public boolean submit(int score, int maxScore, Instant submittedAt, boolean expired) {
if (isGraded()) {
return false; // already submitted/expired — do nothing
}
this.score = score;
this.maxScore = maxScore;
this.submittedAt = submittedAt;
this.status = expired ? AttemptStatus.EXPIRED : AttemptStatus.SUBMITTED;
return true; // this call is the one that graded it
}The service computes the grade with the pure AutoGrader, then records it through that guarded transition. If the attempt is already graded, it returns the already-recorded result — it does not regrade, and it does not overwrite. So the second click after a dropped response gets the same score the first one earned, not a fresh zero:
@Transactional
public GradedResult submitAttempt(UUID attemptId, Map<UUID, Set<String>> answers) {
Attempt attempt = attempts.findById(attemptId).orElseThrow(...);
if (attempt.isGraded()) {
return new GradedResult(attempt.score(), attempt.maxScore()); // idempotent return
}
GradedResult result = grader.grade(questions.findByAssessmentId(attempt.assessmentId()), answers);
boolean expired = attempt.isExpiredAt(clock.instant());
boolean graded = attempt.submit(result.score(), result.maxScore(), clock.instant(), expired);
attempts.save(attempt);
return graded ? result : new GradedResult(attempt.score(), attempt.maxScore());
}Two more decisions earn their keep here. First, starting an attempt is idempotent too: a learner who taps “start” twice (or on two devices) resumes the same in-progress attempt rather than burning two from their budget — the service resumes, it does not restart, and only a genuinely new attempt counts against the limit. Second, a timed attempt submitted past its deadline is graded on whatever was saved and marked EXPIRED — never silently rejected (a learner must not lose work to a clock they could not control) and never silently extended (the deadline is real). That is the exact fix for Monday: the late retry returns the first attempt’s grade; it cannot mint a second, zero-scoring one.
| Failure mode | Naive handler | Scholr’s design |
|---|---|---|
| Double-click submit | Two result rows / two grades | Same grade returned; one row |
| Retry after dropped response | Possible second (worse) grade | First grade returned unchanged |
| Queue redelivery | Reprocessed | No-op via isGraded() guard |
| Submit past deadline | Rejected → lost work, or accepted → extended | Graded on saved answers, marked EXPIRED |
| Concurrent submits (race) | Lost update | @Version lock; first wins |
Integrity, proportionate to the stakes
An assessment engine inevitably meets the question of cheating, and it is as much an ethics question as a technical one. The honest position: match the integrity controls to the stakes, and be transparent about all of them. A low-stakes practice quiz needs none. A graded mid-term benefits from cheap, proportionate signals — randomized question and option order from a larger pool (so neighbors don’t share an answer key), per-attempt question selection, and server-side timing. A high-stakes certification exam may justify stronger measures, but heavy-handed proctoring — webcam surveillance, lockdown browsers, keystroke analysis — carries real costs in privacy, accessibility, false accusations, and learner trust.
| Integrity control | Cost to learner | Proportionate for |
|---|---|---|
| Question/option randomization from a pool | None | Any graded assessment |
| Server-side timing + attempt limits | None | Any graded assessment |
| Tab-switch / paste signals (advisory) | Low; false positives | Mid-stakes, as a flag not a verdict |
| Lockdown browser / webcam proctoring | High; privacy + a11y | High-stakes only, with consent + appeal |
The architectural takeaway is that integrity signals are inputs to a human review, never an automated verdict. A tab-switch is a flag, not a conviction. Building it any other way manufactures false accusations at scale — a correctness failure of a different and more damaging kind.
The real-time tier: live classes, chat, and presence
Now Thursday. Real-time features — a live class video sync, chat, presence (“who’s here”), notifications, a collaborative whiteboard — share one property: the server must push to the client, unprompted, with low latency. The first decision is the transport, and it is genuinely a trade-off rather than a default.
| Transport | Direction | Best for | Cost |
|---|---|---|---|
| WebSocket | Full duplex | Chat, whiteboard, anything the learner sends back | Stateful connections; scaling effort |
| SSE (server-sent events) | Server → client only | Live notifications, a read-only ticker | One-way; reconnection quirks |
| Long polling | Request/response | Fallback where sockets are blocked | Latency + request overhead |
A live class with two-way chat needs WebSockets. (We built the read-only flavor of this in the dashboard mini-series — see the live-dashboard WebSocket backend — but a class is full-duplex and three orders of magnitude larger, which changes everything.) The mistake that froze Scholr’s class was not choosing WebSockets; it was running them the obvious way: one server holding every connection, with the room’s state in that server’s memory.
Scaling WebSockets: why one node always loses, and the fan-out fix
A single node has hard ceilings — file descriptors, memory per connection, CPU to serialize every message to every socket. Forty thousand connections on one box is a coin flip; the moment it tips, every learner in the class is affected, because they are all on that box. Worse, the instinctive patch — a load balancer with sticky sessions pinning each learner to a node — fragments the room: a message published on node A reaches only the learners whose sockets happen to live on node A. Chat splits into parallel universes.
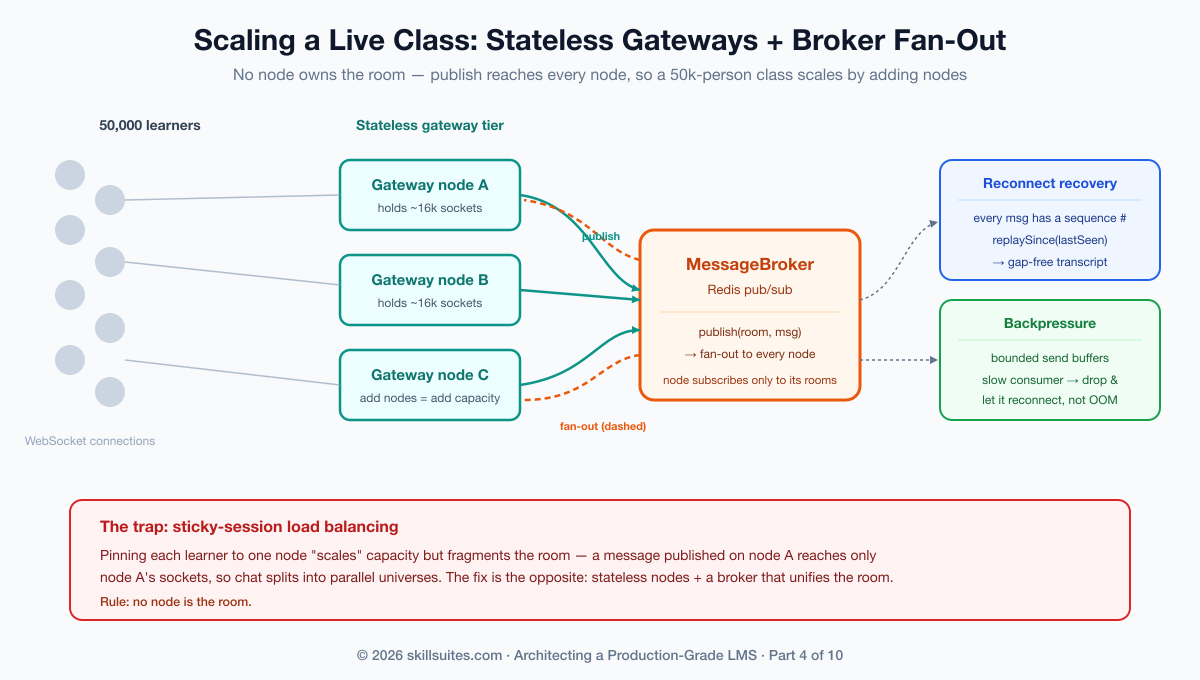
The fix is to make the gateway tier stateless and move room membership out of any one node, into a broker that fans messages out to every node. A node subscribes to a room when it holds the first local connection to it and unsubscribes when the last one leaves; when anyone publishes, the broker delivers to every subscribed node, which relays to its local sockets. No node owns the room; you add nodes to add capacity. Scholr isolates that boundary behind one small port so the rest of the code never knows whether it’s talking to an in-process bus (dev, tests) or Redis pub/sub (production):
public interface MessageBroker {
void publish(String topic, String message); // fan-out to every node
Subscription subscribe(String topic, Consumer<String> onMessage);
interface Subscription extends AutoCloseable { void close(); }
}Above this interface — rooms, presence, chat — nothing changes when you swap the in-memory implementation for a RedisMessageBroker. That is the entire reason to isolate fan-out behind a port: it lets a class scale horizontally without rewriting the class logic. The room itself tracks presence as cheap, derived state and assigns every message a monotonic sequence number (we’ll see why next):
public synchronized long publish(String payload) {
long seq = sequence.incrementAndGet();
recent.add(new SequencedMessage(seq, payload)); // bounded ring buffer
if (recent.size() > BUFFER_SIZE) recent.remove(0);
broker.publish(roomId, seq + ":" + payload); // fan out to all nodes
return seq;
}| Approach | Scales past one node? | Room stays whole? | Verdict |
|---|---|---|---|
| Single node, in-memory room | No | Yes (until it falls over) | Demo only |
| Sticky load balancer, per-node rooms | Capacity yes | No — chat fragments | A trap |
| Stateless gateways + broker fan-out | Yes (add nodes) | Yes (broker unifies) | Our choice |
| Managed real-time service | Yes | Yes | Buy it if fan-out isn’t your edge |
For very large rooms you shard further — partition a single massive room across broker channels, or fan out through a tree of relays so no one publisher hits every node directly — but the principle is unchanged: no node is the room.
Presence at scale is its own trap. The naive “who’s here” implementation broadcasts a join/leave event to every participant on every connect and disconnect — and in a 50,000-person class where connections constantly flap, that is a quadratic storm of presence updates that can dwarf the actual chat traffic. The fix is to treat presence as derived, approximate, and batched: keep the set of present learners as cheap in-memory state (Scholr uses a concurrent set per room), expose a periodically-sampled count rather than a live event per individual, and only push the full roster to the people who actually open it (an instructor’s participant panel), not to all fifty thousand viewers. Presence is the canonical example of state that should be eventually consistent — a count that’s two seconds stale harms no one, while a count that’s exactly right at the cost of a broadcast storm harms everyone. It is never the source of truth for anything billable or graded; it is a display.
The same restraint applies to what you fan out at all. Not every keystroke in a collaborative whiteboard needs to be its own broadcast; batch them into periodic frames. Not every “user is typing” indicator needs delivery guarantees; it’s ephemeral and droppable. Deciding, per message type, between at-most-once and droppable (typing indicators, cursor positions), at-least-once with replay (chat), and strongly consistent (almost nothing in the real-time tier) is the design work that keeps a live class affordable. The cheapest message is the one you chose not to send.
Backpressure and delivery guarantees: the slow consumer and the lost message
Fan-out solves capacity; it does not solve the two problems that actually corrupt a live class. The first is the slow consumer: a learner on hotel Wi-Fi can’t drain messages as fast as a busy room produces them, and an unbounded per-connection buffer turns that one slow client into a server-wide memory leak. The discipline is backpressure — bound every send buffer, and when it overflows, drop that one connection (it can reconnect and recover) rather than let it sink the node. One slow learner must never become everyone’s outage; that is the same fairness lesson as Part 2’s noisy neighbor, applied to sockets.
The second is the lost message on reconnect. Connections drop; that is normal. What is unacceptable is a gap in the chat transcript when they come back. Because every message carries a sequence number, a reconnecting client sends its last-seen sequence and the room replays exactly what it missed, in order:
public synchronized List<SequencedMessage> replaySince(long lastSeenSeq) {
List<SequencedMessage> missed = new ArrayList<>();
for (SequencedMessage m : recent) {
if (m.seq() > lastSeenSeq) missed.add(m); // gap-free, ordered
}
return missed;
}The in-memory buffer is bounded, so a client gone longer than the buffer’s reach is told to reload the full transcript from durable storage rather than handed a partial one — the system never silently presents a hole as complete. Sequence numbers also give you ordering for free: clients render by sequence, so messages that arrive out of order over different paths still display correctly.
| Guarantee | Mechanism | What it prevents |
|---|---|---|
| No server-wide stall | Bounded buffers; drop the slow socket | One client OOM-ing a node |
| Gap-free reconnect | Per-room sequence + replay-since | Missing messages after a drop |
| Correct ordering | Render by sequence number | Out-of-order display |
| Honest history | Bounded buffer → fall back to storage | A partial transcript shown as whole |
The war stories, resolved — and what we’d do differently
Monday’s double-charge was an idempotency hole: a write that assumed the happy path on a network that never promises one. The fix was not “add a button-disable on the client” (that stops nothing once a request is in flight); it was making submission exactly-once at the aggregate and the database, and treating a late submit as a graded-and-expired event rather than a reject-or-extend choice. Thursday’s frozen class was a topology mistake: state trapped on one node, then “fixed” with sticky sessions that fragmented the room. The fix was a stateless gateway tier over a broker that fans out, plus backpressure and sequence-numbered replay so reconnections heal instead of tear.
What would we do differently from day one? We would have made every state-changing endpoint idempotent by default — submission, enrollment, payment — rather than discovering the need one incident at a time; idempotency is cheap to design in and expensive to retrofit. And we would have load-tested the live tier against a realistic concurrency curve before a launch, not after, because real-time failures are the one class of bug your biggest, most visible moment is guaranteed to find first. Both lessons rhyme with the rest of the series: decide the hard property up front, and prove it.
Get the code and run it
Everything above is in the companion repository, evolving the same codebase the series has built since Part 1. Each part has its own branch frozen at that lesson’s checkpoint, and main always holds the latest cumulative code.
# this part's exact code:
git clone https://github.com/muasif80/tutorial-lms-platform.git
cd tutorial-lms-platform
git checkout part-4
# the latest cumulative build is always on main:
git checkout mainVerify it the way the build does — the deterministic grading rules, the idempotent/expiring submission, the attempts policy, tenant isolation, and the real-time fan-out + reconnect recovery all run under one command:
mvn verify # green = grading + exactly-once submission + fan-out/replay all holdWhere each idea in this article lives in the code:
- Deterministic grading —
assessment/AutoGrader.java(pure function) with its spec inAutoGraderTest.java. - Idempotent, exactly-once submission —
assessment/domain/Attempt.java(the guardedsubmit+@Version) andassessment/AssessmentService.java. - Attempts policy + timed expiry —
Assessment.java, the resume-not-restart logic inAssessmentService.startAttempt, proven byTimedAttemptTest.java. - Tenant isolation + RLS for the new tables —
db/migration/V3__assessment.sql. - WebSocket fan-out, presence, and missed-message recovery —
realtime/MessageBroker.java,InMemoryMessageBroker.java, andLiveClassRoom.java, proven inAssessmentAndRealtimeTest.java.
Frequently asked questions
How do I scale WebSockets to tens of thousands of concurrent users?
Don’t keep room state on a single node. Make the WebSocket gateway tier stateless and put a broker (Redis pub/sub or a managed pub/sub service) between nodes: each node subscribes to the rooms it holds connections for, and a published message fans out to every subscribed node, which relays to its local sockets. You then add capacity by adding nodes. Avoid sticky-session load balancing as the scaling strategy — it fragments a room so a message reaches only the node that produced it.
How do I prevent double-counted or duplicated exam submissions?
Make submission idempotent at the aggregate and back it with a database constraint, exactly as you would any critical write. Give the attempt a one-way IN_PROGRESS → SUBMITTED transition guarded by a check that grades only if not already graded, protect it with a @Version optimistic lock, and have a duplicate submit return the already-recorded grade instead of regrading. A retry after a dropped response then yields the same score, never a second one.
WebSockets, SSE, or long polling for live classes?
Use WebSockets when the learner sends data back (chat, whiteboard, reactions) — they’re full-duplex and low-latency. Use SSE for one-way server-to-client streams like live notifications, where it’s simpler. Keep long polling only as a fallback for environments that block sockets. A live class with chat is a WebSocket case; a read-only notification feed is an SSE case.
How do I handle reconnections without losing messages?
Give every message in a room a monotonic sequence number and keep a bounded buffer of recent messages. On reconnect, the client sends its last-seen sequence and the server replays only what came after it, in order — a gap-free transcript. If the gap is older than the buffer, tell the client to reload history from durable storage rather than handing it a partial transcript. Sequence numbers also fix out-of-order display, since clients render by sequence.
Conclusion
Assessments and real-time are where an LMS earns or loses trust in the moments that matter most — the exam a learner stakes a grade on, the live class an instructor stakes a reputation on. We made grading a pure, deterministic function so a score is defensible; made submission exactly-once so a retry can never double-charge; enforced the attempts policy and timed expiry on the server so neither can be gamed; and rebuilt the real-time tier as stateless gateways over a broker that fans out, with backpressure and sequence-numbered replay so a 50,000-person class scales and heals instead of freezing. Scholr’s two bad days are now impossible by construction.
The full, tested implementation — the grading engine, the idempotent submission service, and the fan-out real-time tier, all verified by a build that proves them — is on the part-4 branch of the companion repository. ⭐ Star it to follow the build. Next, in Part 5, we turn every click and submission into a learning-analytics pipeline — events, streaming, and the outbox problem — the system that finally answers “is anyone actually learning?”
