

In Part 1 we designed Scholr’s domain — bounded contexts, a ubiquitous language, the decisive choice of a modular monolith — and drew the reference architecture the series fills in. We deliberately wrote no SQL. Now we descend into the foundation everything rests on: the data model and the multi-tenancy strategy. This is where Scholr’s first real production crisis was hiding all along.
The crisis went like this. One large customer — a training company onboarding a new client — kicked off a bulk import of 200,000 enrollments through Scholr’s admin API. The import ran in one giant transaction, took locks on shared tables, and for ninety seconds every other organization on the platform saw slow pages, timeouts, and failed logins. One tenant’s batch job had become every tenant’s outage. The team’s first instinct was to blame the import. The real culprit was a decision made eighteen months earlier and never revisited: how tenants share the database.
That is the theme of this part. Multi-tenancy is a one-way door. You choose how tenants share — or don’t share — data once, early, and you live with the consequences for years; retrofitting a different model onto a database full of customer data is among the most painful and risky migrations in software. So we are going to make that choice deliberately, build the core data model on top of it, and make a cross-tenant data leak structurally impossible rather than merely unlikely. We will also fix Scholr’s noisy-neighbor problem at its root.
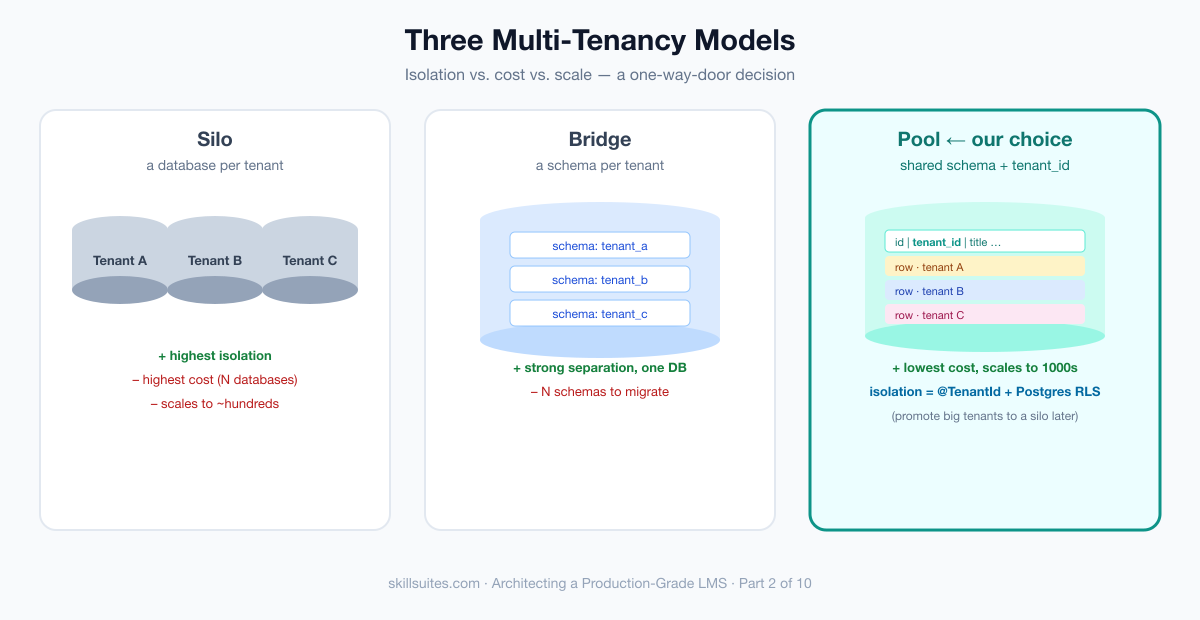
Three ways to be multi-tenant
There are three classic tenancy models, and the entire backend’s cost, isolation, and scaling ceiling follow from which one you pick.

- Silo — a database per tenant. Maximum isolation; one tenant’s load and one tenant’s outage are entirely their own. But the operational cost explodes with tenant count (hundreds of databases to migrate, back up, and monitor), and onboarding a new tenant means provisioning infrastructure.
- Bridge — a schema per tenant in a shared database. A middle ground: strong logical separation, one database to operate, but still hundreds of schemas to migrate, and connection/catalog overhead that bites at scale.
- Pool — a shared database and schema, with a
tenant_idcolumn on every tenant-scoped table. The cheapest to operate and the easiest to scale to thousands of tenants — one schema, one migration, one backup. The catch: isolation is now your application’s responsibility, and one forgottenWHERE tenant_id = ?is a data breach.
| Model | Isolation | Cost / ops | Blast radius | Scale ceiling |
|---|---|---|---|---|
| Silo (DB per tenant) | Highest | Highest (N databases) | One tenant | Low (hundreds) |
| Bridge (schema per tenant) | High | High (N schemas) | One tenant (mostly) | Medium |
| Pool (shared + tenant_id) | App-enforced | Lowest (one schema) | Whole platform if you slip | Highest (thousands) |
For a B2B SaaS LMS like Scholr — many organizations, most of them small or mid-sized, all wanting fast onboarding — the right default is pool, with an escape hatch: a handful of very large or highly regulated tenants can be promoted to their own silo later, because the application code doesn’t care which physical database it’s talking to. The rest of this part makes pool tenancy safe.
Making isolation structural, not hopeful
The fatal weakness of pool tenancy is the human one: somewhere, someday, an engineer writes a query that forgets the tenant filter, and now one org can read another’s data. “Be careful” is not a strategy. We make leakage impossible with two independent layers.
Layer one: the application filters automatically
We never want application code to hand-write tenant_id = ?, because anything hand-written is something that can be forgotten. Hibernate 6 gives us this for free with @TenantId: annotate the tenant column once, provide a resolver that knows the current tenant, and Hibernate transparently adds the tenant condition to every read and sets it on every write.
@Entity
@Table(name = "courses")
public class Course {
@Id
private UUID id;
@TenantId // Hibernate fills this on save,
@Column(name = "tenant_id", updatable = false)
private UUID tenantId; // and filters every query by it
@Column(nullable = false)
private String title;
// ...
}The resolver is the one place that knows “who is this request’s tenant,” read from a thread-local that the web tier populates from the authenticated principal. It must never return null: Hibernate opens sessions before any web request exists — at startup, when it bootstraps the repositories, for background work — so an unset tenant falls back to a reserved SYSTEM_TENANT rather than crashing:
UUID resolveCurrentTenantIdentifier() {
TenantId tenant = TenantContext.get();
return tenant != null ? tenant.value() : SYSTEM_TENANT; // never null
}One non-obvious wiring detail, learned the hard way: the @TenantId annotation alone flips Hibernate’s SessionFactory into multi-tenant mode, and if the resolver isn’t actually handed to Hibernate at build time, the very first session dies with “SessionFactory configured for multi-tenancy, but no tenant identifier specified.” Don’t leave that to bean auto-detection — register the resolver explicitly through a HibernatePropertiesCustomizer so the wiring is order-independent (see shared/MultiTenancyConfig.java in the repo). With that in place, a query like courseRepository.findAll() silently becomes “all courses for this tenant.” There is no tenant filter to forget, because there is no tenant filter to write.
Layer two: the database refuses to leak
Application-level filtering is necessary but not sufficient — a raw SQL report, a buggy native query, or a future service in another language could still bypass it. So we add PostgreSQL Row-Level Security as a hard floor. With RLS, the database itself attaches a tenant predicate to every query against a protected table, enforced by the engine, not the app:
alter table courses enable row level security;
create policy tenant_isolation on courses
using (tenant_id = current_setting('app.tenant_id', true)::uuid);The application sets a session variable — SET app.tenant_id = '...' — at the start of each transaction, and from then on Postgres makes it impossible to see another tenant’s rows, even if the query “forgot” the filter and even if Hibernate were bypassed entirely. This is the difference between “we filter by tenant” and “the database cannot return another tenant’s data.” Defense in depth: the app filter for ergonomics and performance, RLS for the guarantee.
Wiring RLS in is a small, one-time piece of plumbing: at the start of each transaction the app runs SET LOCAL app.tenant_id = '...' on the connection (a transaction-scoped listener does this from the same TenantContext the ORM reads), so the database GUC and the ORM filter always agree on who the tenant is. And the escape hatch stays open. Because the code only ever talks to “the database” through the connection pool, promoting a heavyweight or regulated tenant to its own physical database later is a routing-and-config change, not a rewrite — pool tenancy doesn’t trap you in a shared database forever, it just defers that cost until a specific tenant is worth it.
The core data model
With isolation handled, we can model the data. The shape follows directly from Part 1’s bounded contexts, and one distinction from Part 1 drives the whole design: identity is global, but membership and roles are per-organization.
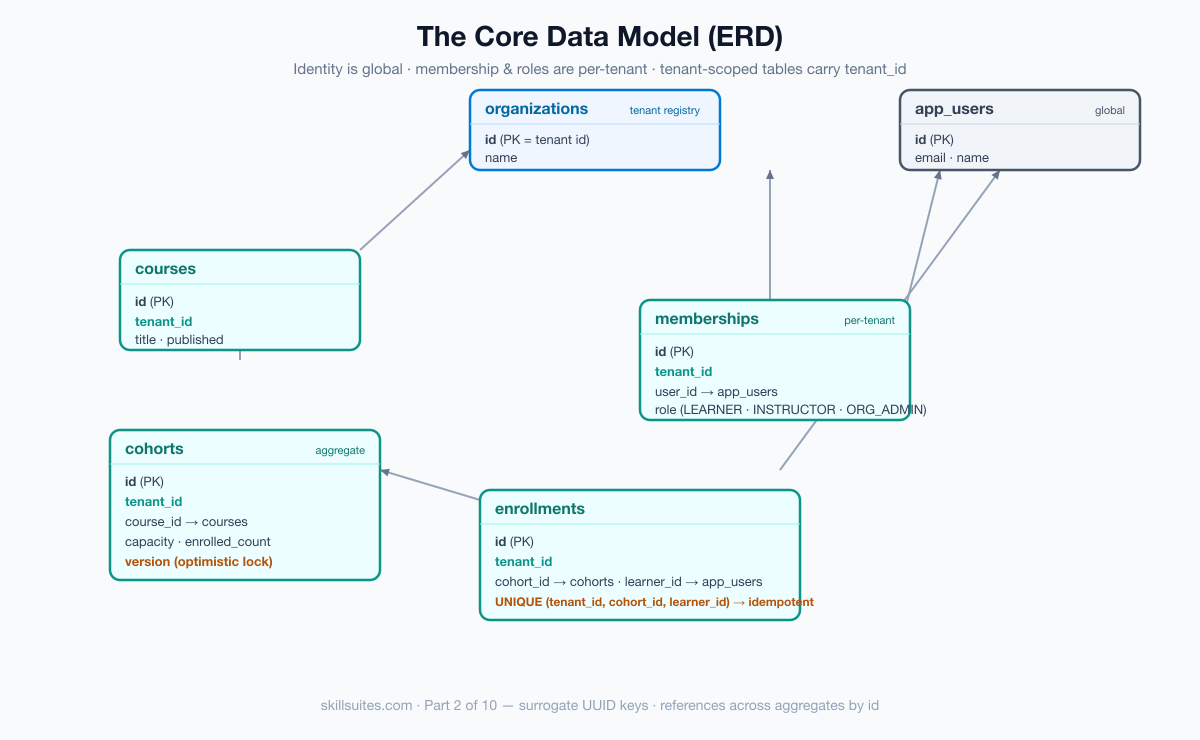
- organizations — the tenant registry. An organization’s primary key is the tenant id. This table is deliberately not tenant-scoped: an operator lists organizations across tenants.
- app_users — people, global. The same human can be a learner in one org and an instructor in another, so the user record is shared, not duplicated per tenant.
- memberships — the per-tenant join between a user and an organization, carrying the role. This is where “who may do what, and where” lives, and it is tenant-scoped.
- courses, cohorts, enrollments — the learning data from Part 1’s contexts, all tenant-scoped.
A few modeling choices worth stating, because they age well. We use surrogate UUID keys everywhere rather than natural keys — UUIDs are stable, don’t leak counts or ordering, and let a client generate an id before a round-trip (useful for idempotency). We reference across aggregates by id, not by object association — a cohort holds a courseId, not a mapped Course — exactly the boundary discipline from Part 1, which keeps the aggregates independently loadable and the modules decoupled. And for anything you’ll need to audit or undo, prefer soft deletes and append-only history over destructive updates; in a system that issues certificates and tracks compliance, “what did the record say last March?” is a question you will be asked.
A note on the keys themselves: random UUIDv4s scatter inserts across the primary-key index and hurt write locality on high-volume tables, so prefer time-ordered ids (UUIDv7 or ULIDs) for the busy tables like enrollments — you keep the opacity and client-generation benefits while regaining the index locality you’d get from a sequence. And resist modeling everything as a hard row you mutate in place: enrollments get cancelled, courses get unpublished, memberships get revoked. Represent those as state transitions or append-only events rather than DELETEs, so the platform can always answer “what was true, and when” — exactly what compliance, billing disputes, and the analytics pipeline in Part 5 will demand of it.
Transactional boundaries: what must be atomic
Part 1 promised that the seat invariant — never oversell a cohort — would be enforced in a single transaction. Part 2 delivers it. The pure Cohort aggregate from Part 1 becomes a persistent entity, keeping its invariant logic and gaining an optimistic-lock version:
@Entity
public class Cohort {
@Id private UUID id;
@TenantId @Column(name = "tenant_id") private UUID tenantId;
private int capacity;
@Column(name = "enrolled_count") private int enrolledCount;
@Version private long version; // optimistic lock
public Enrollment enroll(UUID learnerId) {
if (enrolledCount >= capacity) {
throw new CohortFullException(id); // the invariant, enforced here
}
enrolledCount++;
return new Enrollment(UUID.randomUUID(), id, learnerId);
}
}The service wraps this in a transaction and makes it idempotent — a retried request (a flaky network, an impatient user double-clicking, a queue redelivery) must not create a second enrollment:
@Transactional
public Enrollment enroll(UUID cohortId, UUID learnerId) {
return enrollments.findByCohortIdAndLearnerId(cohortId, learnerId)
.orElseGet(() -> {
Cohort cohort = cohorts.findById(cohortId).orElseThrow(...);
Enrollment enrollment = cohort.enroll(learnerId); // invariant + seat++
cohorts.save(cohort); // version-checked update
return enrollments.save(enrollment);
});
}Two mechanisms keep the seat invariant true even when two requests race for the last seat. The in-aggregate check rejects an over-capacity enroll; and the @Version optimistic lock means that if two transactions both read enrolled_count = 9 and both try to write 10, the database accepts one and rejects the other with a stale-version error (to be retried), so the seat is never double-sold. Crucially, this needs no distributed lock, because the cohort and its seat count live in one aggregate and one row. That is the dividend of Part 1’s modular monolith: the rules that must be exactly right are exactly right, inside one transaction.
Equally important is knowing what does not belong in that transaction. A learner’s aggregate progress across a hundred lessons, the analytics that feed instructor dashboards, the search index — these are eventually consistent, updated asynchronously off the event stream we build in Part 5. Forcing them to be synchronous would couple everything to everything and re-create the noisy-neighbor problem. Strong consistency inside the aggregate; eventual consistency across contexts.
Why optimistic locking rather than a pessimistic SELECT ... FOR UPDATE? Because enrollment conflicts are rare — the last seat is contended for a few milliseconds, a few times, in a cohort’s whole life. Optimistic locking pays nothing on the common, uncontended path, whereas a row lock serializes every single enroll and invites lock waits and deadlocks under a traffic spike. The price of optimism is that the loser of a genuine race gets a stale-version error, so the caller (or a thin retry wrapper around the service) simply retries: re-read the cohort, re-check the invariant, save again. On the retry the seat is really gone, so the second learner correctly gets “cohort full.” Pessimistic locking earns its keep when conflicts are the norm; for seats, where they’re the rare exception, optimism wins.
Designing the API
The data model needs a contract. For an LMS, plain REST is the right default over GraphQL: the resources are well-bounded, caching is straightforward, and you avoid GraphQL’s operational complexity (query-cost analysis, N+1 resolution, bespoke authorization per field) until you have a concrete reason to pay for it. GraphQL earns its place when you have many heterogeneous clients fetching wildly different shapes; a focused LMS API rarely does at first.
| Concern | REST (our choice) | GraphQL |
|---|---|---|
| Fit for bounded resources | Excellent | Overkill early |
| Caching | HTTP-native | Manual |
| Authorization | Per endpoint | Per field (complex) |
| Over/under-fetching | Possible | Solved |
Good REST for this domain means a few disciplines applied consistently: model resources, not actions (POST /api/cohorts/{id}/enrollments, not /enrollLearner); paginate with cursors, not offsets, so a tenant’s growing table doesn’t make page 900 a table scan; version the API (a URL prefix or header) so you can evolve without breaking clients; and surface rate-limit state in response headers so clients can back off politely. Above all, make writes idempotent — our enroll endpoint already is, via the find-or-create service and the unique constraint on (tenant_id, cohort_id, learner_id), so a client can safely retry a request it isn’t sure landed:
POST /api/cohorts/{cohortId}/enrollments
X-Tenant-Id: 8f1c... # in production, derived from the auth token
{ "learnerId": "a2b9..." }
-> 200 OK { "id": "...", "cohortId": "...", "learnerId": "..." }
(re-POSTing the same learner returns the same enrollment, not a duplicate)Authentication and authorization
Enterprise customers will not adopt an LMS they can’t plug into their identity provider, so OIDC/SSO (and often SAML) is table stakes — authentication is federated to the customer’s IdP, and your system trusts a signed token. The interesting part is authorization, and it has two layers.
Roles (RBAC) grant coarse capabilities and live on the membership, per tenant: a LEARNER, an INSTRUCTOR, an ORG_ADMIN. Because the same human can be an instructor in one org and a learner in another, the role is a property of the membership, never of the global user. But roles alone can’t express “an instructor may grade only their own cohorts” — that depends on the relationship between the actor and the specific resource, which is attribute-based (ABAC).
| RBAC | ABAC | |
|---|---|---|
| Answers | “What role do you have here?” | “What is your relationship to this resource?” |
| Example | Org admins manage members | Instructors grade only their cohorts |
| Cost | Cheap, cacheable | Needs resource context |
A production system uses both: RBAC for the broad gate, ABAC for the fine-grained checks. And because every request hits the authorization path, the role/permission lookup is a hot path — cache the membership and its roles per (user, tenant) in Redis with a short TTL, so you’re not querying memberships on every call. Authorization that’s correct but slow is its own outage.
Migrating the schema without taking the platform down
A pool model has one schema, which is a gift (one migration) and a responsibility (that migration runs against everyone’s data at once, while they’re using it). The technique is expand/contract — never a destructive change in a single step. To rename a column or change a type, you expand (add the new shape, write to both), backfill in batches, switch reads, then contract (drop the old shape) in a later release:
-- V2: expand — add the new column, keep the old one
alter table courses add column subtitle varchar(255);
-- app now writes both; a batched backfill copies historical rows
-- V3 (a later release): contract — once nothing reads the old column
alter table courses drop column old_subtitle;Two more rules keep migrations from becoming the next outage. Build indexes without locking — Postgres’s CREATE INDEX CONCURRENTLY doesn’t block writes, unlike a plain CREATE INDEX that would freeze a busy table. And backfill in bounded batches with pauses, never one giant UPDATE that locks millions of rows — which is precisely the mistake at the heart of Scholr’s incident.
Fairness: fixing the noisy neighbor
Now we can name and fix what actually broke Scholr. In a pool model, tenants share a database, a connection pool, and worker capacity — so without fairness controls, one tenant’s heavy job is everyone’s problem. Three controls turn shared infrastructure from a liability into the cheap, scalable asset it should be:
- Move bulk work off the request path. A 200,000-row import has no business running synchronously inside an API call. It becomes a queued job, processed in bounded batches (say, 500 rows per transaction) with brief pauses, so it never holds long locks and never monopolizes the database.
- Cap concurrency per tenant. A single tenant may use, say, two background workers at a time; their eleventh batch waits behind their tenth, not behind another tenant’s traffic. One tenant can be slow for themselves without being slow for anyone else.
- Partition the connection pool. Reserve a slice of database connections for interactive traffic so that bulk jobs can never starve logins and page loads of connections — the specific failure Scholr saw.
The war story, resolved — and what we’d do differently
Scholr’s ninety-second platform-wide brownout was never really about an import. It was a tenancy model with no fairness controls and a bulk operation that ran as one giant locking transaction. The fix was not a bigger database; it was the design of this entire part: pool tenancy with isolation enforced by both Hibernate and RLS, bulk work moved to batched async jobs with per-tenant concurrency caps, and a connection pool that protects interactive traffic. After it shipped, a tenant’s largest import was a non-event for everyone else.
What would we do differently? We would treat the tenancy decision as the one-way door it is from day one, and prototype it against a realistic multi-tenant dataset — hundreds of tenants, lopsided sizes — rather than three demo orgs that hide every fairness problem. We would add RLS at the start, not after the first scare, because retrofitting it onto live tables is fiddly. And we would build the bulk-import path as an async, batched, per-tenant-capped job from the first version, because “we’ll make it async later” is how you schedule your own outage.
Get the code and run it
Everything in this part is in the companion repository, and you can run it in a minute. The repo follows a simple convention: each part has its own branch frozen at that lesson’s checkpoint, and main always holds the latest cumulative code — so by the final part, main is the whole platform.
# this part's exact code:
git clone https://github.com/muasif80/tutorial-lms-platform.git
cd tutorial-lms-platform
git checkout part-2
# the latest cumulative build is always on main:
git checkout mainVerify it the same way CI does — compile, run the unit seat-invariant test, the ArchUnit boundary checks, and the Spring test that proves tenant isolation and idempotent enrollment:
mvn verify # green = isolation + idempotency + the seat invariant all hold
# or, with Docker only:
docker build -t scholr-lms .To drive it by hand, start the app and walk the flow — notice how the tenant rides in on a header (in production it comes from the authenticated token, never the client):
mvn spring-boot:run
# 1) create a tenant
curl -XPOST localhost:8080/api/organizations \
-H 'Content-Type: application/json' -d '{"name":"Acme"}'
# -> { "id": "<TENANT>", "name": "Acme" }
# 2) act INSIDE that tenant (the header carries the tenant id)
curl -XPOST localhost:8080/api/courses \
-H 'X-Tenant-Id: <TENANT>' -H 'Content-Type: application/json' \
-d '{"title":"Onboarding"}'
# create a cohort, then POST an enrollment twice — you get the SAME
# enrollment back the second time, because the operation is idempotent.Where each idea in this article lives in the code:
- Automatic tenant filtering — the
@TenantIdcolumn on every tenant-scoped entity (e.g.catalog/domain/Course.java) plus the resolver inshared/MultiTenancyConfig.java. - Database-enforced isolation (RLS) —
src/main/resources/db/migration/V1__init.sql. - The transactional, idempotent seat invariant —
enrollment/domain/Cohort.java+enrollment/EnrollmentService.java. - The proof —
MultiTenancyAndEnrollmentTest.javaasserts isolation, idempotency, and the seat cap on a real persistence stack.
Frequently asked questions
Database-per-tenant or a shared database with a tenant_id?
For most B2B SaaS, a shared database with a tenant_id (the “pool” model) wins on cost and scale — one schema, one migration, thousands of tenants — provided you make isolation structural with an application-level filter (Hibernate @TenantId) plus PostgreSQL Row-Level Security. Keep an escape hatch to promote a few very large or regulated tenants to their own database.
How do I prevent cross-tenant data leaks?
Don’t rely on remembering a WHERE tenant_id. Enforce it in two independent layers: the ORM filters and populates the tenant automatically (so there’s no filter to forget), and the database itself rejects cross-tenant reads via Row-Level Security (so even a raw query or a future service can’t leak). Defense in depth makes a leak structurally impossible rather than merely unlikely.
REST or GraphQL for an LMS API?
Start with REST. An LMS has well-bounded resources, benefits from HTTP-native caching, and avoids GraphQL’s per-field authorization and query-cost complexity. Adopt GraphQL only when you have many heterogeneous clients fetching very different shapes and the over/under-fetching pain is real.
How do I run schema migrations without downtime?
Use the expand/contract pattern: add the new shape, write to both, backfill in bounded batches, switch reads, then drop the old shape in a later release. Build indexes with CREATE INDEX CONCURRENTLY so you don’t lock a busy table, and never run one giant UPDATE backfill.
Conclusion
The backend is where multi-tenancy stops being a slogan and becomes a set of concrete, irreversible decisions. We chose pool tenancy and made it safe with two layers of isolation; modeled the data so that identity is global and membership is per-tenant; enforced the seat invariant transactionally with optimistic locking; designed an idempotent REST API; layered RBAC with ABAC for authorization; and made schema changes and bulk jobs safe for every tenant at once. Scholr’s noisy-neighbor outage is now impossible by construction.
The full, tested implementation — the JPA entities, the @TenantId wiring, the RLS migration, and the idempotent enrollment service, all verified by a build that proves tenant isolation and the seat invariant — is on the part-2 branch of the companion repository. ⭐ Star it to follow the build. Next, in Part 3, we tackle the layer where an LMS’s cost and reliability go to die: serving course video at scale. If you enjoy this systems-design thinking, our production engineering playbook applies the same discipline to AI.
