

By Part 5 Scholr could record everything a learner does and trust the data. But recording learning is not the same as driving it. A learner who can’t find the right course leaves; a learner who finishes one course and is shown nothing relevant next simply stops. Discovery — search, recommendations, and the gentle guidance toward the next thing — is not a garnish on an LMS, it is the engine of engagement. And it is the part teams most often ship as an afterthought: a WHERE title LIKE '%query%', a “popular courses” widget, and a hope. This part builds discovery as the first-class system it deserves to be: real catalog search (keyword, semantic, and hybrid), a recommendation engine that survives the cold-start problem, and an AI tutor that helps without hallucinating.
Scholr’s discovery crisis was quieter than the earlier outages but cost more in the long run. The content team shipped a big catalog refresh — renamed tracks, new descriptions, retired courses — through a bulk update. The primary database was correct instantly. The search index, rebuilt by a nightly job, was hours stale: learners searched for the new track names and got nothing, searched for retired courses and got dead links, and the “no results” rate spiked all afternoon while support tickets piled up. Nobody had broken search; search had simply been built as a thing that drifts from the truth. The fix — an event-driven indexing pipeline fed by Part 5’s stream, plus zero-downtime reindexing — is the backbone of everything below.
Catalog search: more than a LIKE query
Full-text search is a solved problem, and the solution is not the database’s LIKE. A dedicated search engine — OpenSearch or Elasticsearch — exists because good search is a stack of concerns the relational database was never meant to handle: analyzers that tokenize and stem text so “running” matches “run”; typo tolerance (fuzzy matching) so a misspelled query still finds the course; facets so a learner can filter by level, topic, or duration; and relevance ranking that orders results by more than lexical match. That last point is where search becomes a product rather than a feature.
Relevance is the heart of it, because the right answer is rarely the most literal one. A query for “python” should not return forty courses in arbitrary order; it should rank by a blend of how well the text matches and business signals: a course’s popularity, its completion rate (a course people actually finish is a better result than one they abandon), and recency. Scholr makes this explicit — a hit’s score is the base text match multiplied by a signal boost, so relevance is “does it match” times “is it any good,” not match alone:

double score(CourseDocument doc, ...) {
double base = /* lexical and/or semantic match, by mode */;
if (base <= 0) return 0;
// popular, well-completed courses get a modest, tunable boost
double signalBoost = 1.0 + Math.log1p(doc.popularity()) * 0.05 + doc.completionRate() * 0.1;
return base * signalBoost;
}The weights here are hand-set for clarity; a mature search team learns them from click and completion data. But the shape is the lesson: ranking signals are first-class inputs, and the ones that matter for learning (do people finish this course?) are specific to the domain, not something a generic search engine knows to apply.
Underneath ranking sit the text-processing details that separate search that feels good from search that frustrates. Analyzers decide how text becomes searchable tokens: lower-casing, removing stop words, and stemming so “running,” “ran,” and “runs” all match the root “run” — without it, a query for “running” misses a course titled “Run Faster.” Typo tolerance (fuzzy matching within an edit distance) means “javascrpt” still finds JavaScript courses, which matters enormously because a meaningful fraction of real queries are misspelled and a literal engine returns nothing for them. Facets turn a flat result list into a navigable one — filter by level, topic, duration, language — and they are computed as aggregations over the matching set, another thing a search engine does well and a LIKE query cannot do at all. And synonyms (curated mappings like “JS” → “JavaScript”, “ML” → “machine learning”) patch the gaps keyword matching leaves before you even reach semantic search. None of these is exotic; together they are the difference between a search box learners trust and one they abandon after two empty results.
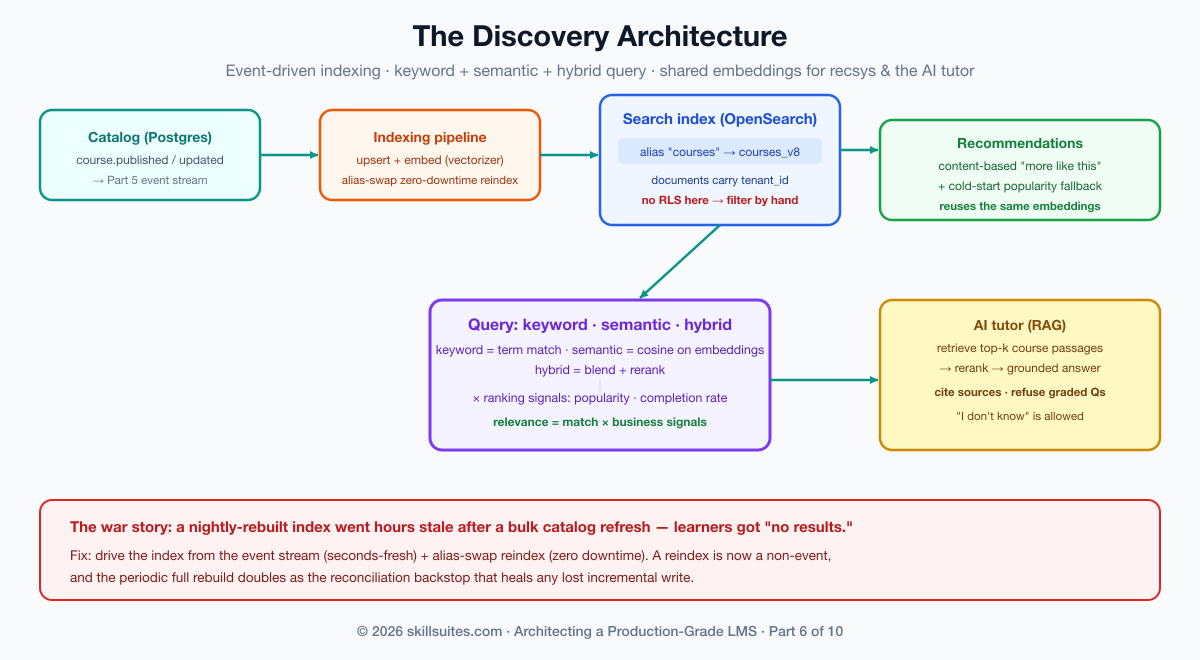
The indexing pipeline: keeping search fresh without downtime
Now Scholr’s actual bug. A search index is a derived store — a denormalized copy of catalog data, optimized for query, that must be kept in step with the system of record. The nightly-rebuild approach guarantees staleness; the fix is to feed the index from the event stream built in Part 5. When a course is published or updated, that event drives a single-document upsert into the index within seconds, not hours. The index becomes a projection — exactly the pattern Part 5 established for progress, now applied to search.
But incremental upserts don’t cover the case that broke Scholr: a structural change — a new analyzer, a changed field mapping, a full backfill — requires rebuilding the whole index. Do that in place and you either take search down or serve half-built, wrong results while it fills. The production technique is alias-based zero-downtime reindexing: searches always hit a stable alias (courses) that points at a concrete physical index (courses_v7). To reindex, you build a brand-new physical index alongside the live one, fill it completely, and then atomically repoint the alias:
public String reindexAll(List<CourseDocument> documents) {
String newIndex = "courses_v" + version.incrementAndGet();
index.createIndex(newIndex);
for (CourseDocument doc : documents) {
index.index(newIndex, doc); // fill the NEW index while the OLD one still serves traffic
}
index.assignAlias("courses", newIndex); // atomic flip — readers never see a half-built index
return newIndex;
}Throughout the rebuild, every search keeps hitting the old index and getting complete, correct results. The instant the alias flips, the next search hits the fully-populated new index. There is no window of partial results and no downtime — the failure mode that generated an afternoon of “no results” tickets becomes structurally impossible. The same alias indirection makes rollback trivial: if the new index is wrong, point the alias back.
Two subtleties keep this honest in production. First, a derived index is itself a place data can diverge from the source — the same dual-write risk Part 5’s outbox addressed — so the index should be driven by the same reliable event stream rather than a best-effort “also write to search” call in the request path; if a search write is ever lost, the periodic full reindex is the backstop that heals it. Second, a backfill during reindex must read a consistent snapshot of the catalog, or the new index captures a smear of mid-flight changes; you reindex from a point-in-time read and then let the live event stream carry forward any changes since that point. The combination — event-driven freshness in the hot path, snapshot-based reindex with a stream catch-up, and a reindex that is itself the reconciliation backstop — is what makes search both seconds-fresh and self-healing.
| Index update path | Mechanism | Keeps the index… |
|---|---|---|
| Incremental upsert | Event stream drives a single-document write | Seconds-fresh on every catalog change |
| Full reindex (alias swap) | Build new physical index, fill, repoint alias | Safe for mapping/analyzer changes; zero downtime |
| Reindex as backstop | Periodic rebuild from a consistent snapshot | Self-healing if any incremental write was lost |
Semantic and hybrid search: matching meaning, not just words
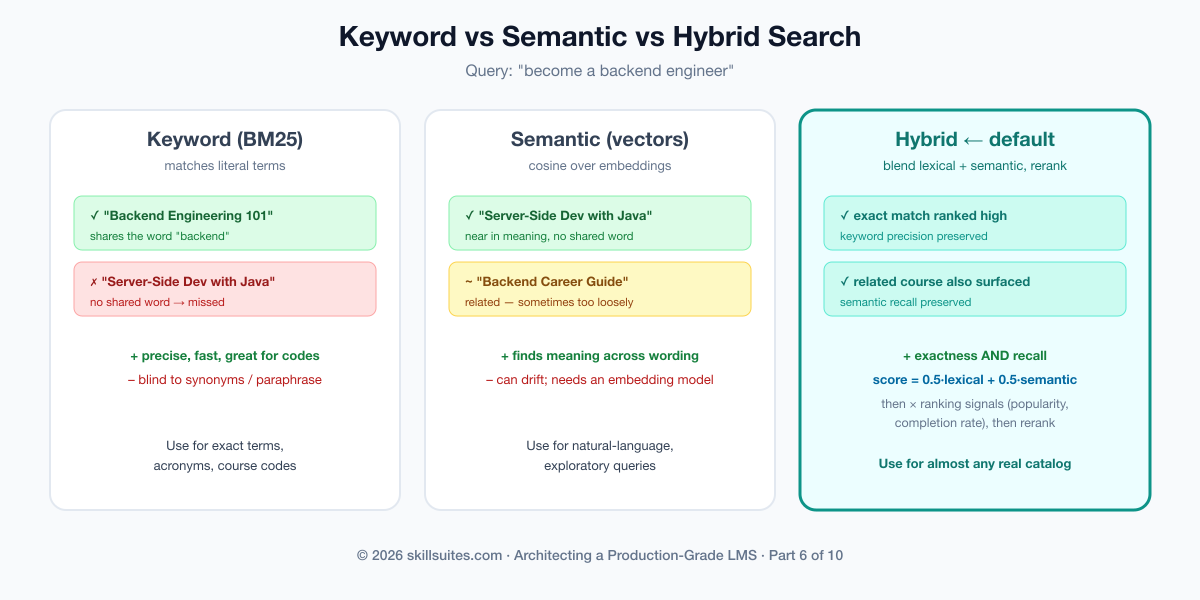
Keyword search has a ceiling, and it is built into how it works: it matches words, so a learner searching “become a backend engineer” misses a superb course titled “Server-Side Development with Java” because they share no terms. Semantic search closes that gap. Text — both the course content and the query — is converted by an embedding model into a vector in a space where meaning, not spelling, determines proximity; “backend engineer” and “server-side development” land near each other. Search becomes a nearest-neighbor problem over those vectors (cosine similarity), and conceptually-related courses surface even with zero shared words.
Scholr isolates the embedding behind a seam so the rest of the stack is independent of which model produces the vectors — the same port discipline used for the broker in Part 4 and the event publisher in Part 5:
// a deterministic stand-in in the repo; a real embedding model plugs into this one seam
Map<Integer, Double> vectorize(String text);
double cosine(Map<Integer, Double> a, Map<Integer, Double> b);But semantic search is not strictly better — it trades precision for recall. A query for an exact course code, an acronym, or a specific proper noun is best served by literal keyword matching; semantics can “helpfully” drift to something related but wrong. The mature answer is hybrid search: run both, combine the lexical score and the semantic score, and rerank. You get the exactness of keywords and the recall of meaning, which is why hybrid is the pragmatic production default. Scholr exposes all three modes and blends them in hybrid:
double base = switch (mode) {
case KEYWORD -> lexical; // term must be present — precise
case SEMANTIC -> semantic; // cosine only — high recall
case HYBRID -> 0.5 * lexical + 0.5 * semantic; // both, then rerank — the default
};| Mode | Strength | Weakness | Use when |
|---|---|---|---|
| Keyword (BM25) | Exact, predictable, fast; great for codes/acronyms | Blind to synonyms and paraphrase | The query is literal and specific |
| Semantic (vectors) | Finds meaning across different wording | Can drift to related-but-wrong; needs a model | Natural-language, exploratory queries |
| Hybrid (our default) | Exactness + recall, reranked | More moving parts to tune | Almost always, for a real catalog |
A note on the same architecture powering AI features: the embeddings that drive semantic search are the very same vectors a retrieval-augmented tutor uses to find relevant course passages. Build the vector layer once and it serves both discovery and the AI tutor below — the connective tissue our production-LLM playbook calls the retrieval layer.
Recommendations and the cold-start problem
Search answers “find me X”; recommendations answer the more valuable question the learner didn’t ask: “what should I do next?” There are two classic families, and the choice between them is really a question about how much data you have.
Content-based recommendation ranks items by similarity of their content — recommend courses whose embeddings are near one the learner liked. Collaborative filtering ignores content and learns from behavior — “learners who took this also took that.” Mechanically, it treats the learner-by-course interaction matrix as something to mine: find learners whose history overlaps yours (“learners like you”), or factor the matrix into latent learner and course vectors whose dot product predicts affinity, and recommend the high-scoring courses you haven’t taken. It is powerful precisely because it captures patterns content can’t see — that people who finish a SQL course tend to love a particular data-visualization one for reasons no description would reveal. But it needs a dense history of interactions to work. That dependency is the trap, and it has a name: the cold-start problem. A brand-new platform, a brand-new course, or a brand-new learner has no interaction history, so collaborative filtering has nothing to compute, and a naive recommender shows an empty shelf at the exact moment a first impression is being formed.
The production answer is not to choose but to blend and graduate: lead with content-based and popularity while the platform is young and signal-poor, fold in collaborative signals as interaction data accumulates, and weight the blend by confidence per learner — a learner with hundreds of interactions leans collaborative, a newcomer leans content-based and popular. New courses get the same treatment from the item side: a freshly published course has no behavioral signal, so it rides content similarity until enough learners interact with it to earn collaborative standing. The cold-start problem is never “solved” once; it is continuously managed at the edges where new learners and new courses enter.
Scholr handles cold-start honestly rather than pretending. Content-based recommendations work from day one because they need only item content, not behavior — “more like this” is a cosine query over embeddings:
public List<CourseDocument> similarTo(UUID seedCourseId, int limit) {
CourseDocument seed = /* the course the learner liked */;
return allCourses.stream()
.filter(d -> !d.courseId().equals(seedCourseId))
.sorted(by(d -> vectorizer.cosine(seed.vector(), d.vector())).reversed())
.limit(limit).toList();
}And for the learner with no seed and no history at all, the fallback is a sensible non-personalized ranking — the most popular, best-completed courses — because a good default beats a blank page, and it gathers the very interaction signal that lets collaborative filtering take over later:
public List<CourseDocument> popular(int limit) { // the cold-start answer
return allCourses.stream()
.sorted(by(CourseDocument::popularity).thenBy(completionRate).reversed())
.limit(limit).toList();
}| Approach | Needs | Cold-start behavior | Graduate to it when |
|---|---|---|---|
| Content-based (start here) | Item content / embeddings | Works from day one | You have any catalog at all |
| Collaborative filtering | Dense interaction history | Fails — no signal yet | You have rich behavioral data |
| Popularity fallback | Aggregate counts | The honest default | A learner has no personal signal |
Personalization and adaptive learning paths
Recommendations point across the catalog; adaptive learning points within it, sequencing what a single learner does next based on their demonstrated mastery. The signals already exist — Part 4’s deterministic assessment scores and Part 5’s progress events — and the job is to turn them into a path: when a learner aces the early quizzes, skip ahead or raise difficulty; when they stumble on a concept, insert remediation before moving on; respect prerequisites so the next-best lesson is also a valid one.
The mechanism worth getting right is difficulty calibration, and it has a well-trodden theory behind it. Rather than a hand-wired “if score > 80% then skip,” mature adaptive systems model each learner’s latent ability and each item’s difficulty on the same scale (the idea at the core of Item Response Theory and computerized adaptive testing), then serve the next item targeted near the learner’s current estimated ability — hard enough to be informative, not so hard it demoralizes. Every answered question sharpens both estimates. You do not need the full psychometric apparatus to start; even a coarse three-band “remediate / stay / advance” decision driven by recent mastery is a large improvement over a fixed linear path. The discipline that keeps any of it honest is the same as recommendations: adaptivity is a function of recorded mastery signals, recomputable and explainable, not a black box. A learner (or an instructor) should be able to ask “why was I shown this next?” and get an answer grounded in their own results — never an opaque score from a model that can’t show its work.
AI tutoring over course content, done safely
The most-requested AI feature in any LMS is a tutor: “let me ask questions about this course and get answers.” It is also the easiest to get dangerously wrong, because a confident, fluent, incorrect answer from an authoritative-looking tutor is worse than no tutor at all. The safe design is retrieval-augmented generation grounded in the learner’s own materials: when a learner asks a question, retrieve the most relevant passages from their course content (using the same embeddings that power semantic search), and instruct the model to answer only from those passages, with citations, and to say “I don’t know, here’s where to look” when the materials don’t contain the answer.
Concretely, the retrieval pipeline has a few stages and each one is a place to protect quality. Course content is split into chunks sized so a passage is self-contained but not bloated; each chunk is embedded once and stored in the vector index (the same one search uses). At question time the learner’s query is embedded, the top-k most similar chunks are retrieved, those candidates are reranked (a cross-encoder or a heuristic that weighs exact-term overlap, recency, and source authority), and only the best few are placed in the model’s context with an instruction to answer strictly from them. Get the retrieval wrong and no amount of prompt cleverness saves you — a model asked to ground its answer in irrelevant passages will either refuse or, worse, paper over the gap. Retrieval quality is tutor quality.
Two guardrails are then non-negotiable, and both come straight from the production engineering playbook. First, ground and cite: every answer links back to the source passage, so a learner can verify it and a hallucination has nowhere to hide — an uncited claim is a bug, not an answer, and “the materials don’t cover this” is a perfectly good response. Second, never let the tutor answer a graded question. The tutor must know which content is assessment material and refuse to do the learner’s exam for them — an AI that cheerfully solves the test it is supposed to be preparing the learner for has inverted its own purpose. The boundary, as ever, is judgment versus arithmetic: the tutor explains and points, the deterministic grader from Part 4 scores, and the two never trade places.
| AI-tutor guardrail | What it prevents | How |
|---|---|---|
| Grounded in retrieved course content | Confident answers from outside the materials | Answer only from retrieved chunks; refuse otherwise |
| Mandatory citations | Unverifiable / hallucinated claims | Every answer links its source passage |
| “I don’t know” is allowed | Plausible-sounding fabrication | Explicit fallback when retrieval is weak |
| Assessment content is off-limits | The tutor doing graded work | Tag exam material; refuse to answer it |
Evaluating search and recommendations: the metrics teams skip
Discovery is the one area teams most often ship without measuring, which is strange because it is eminently measurable. Offline, you evaluate ranking quality against a labeled set with metrics like precision@k (of the top k results, how many were relevant), recall (of all relevant items, how many surfaced), and NDCG (which rewards putting the best results highest, not just somewhere on the page). Offline evaluation is cheap and fast, perfect for catching regressions before they ship — but it only measures against the relevance labels you already have, which is also its blind spot: it can’t tell you whether a genuinely better result you’ve never labeled is being suppressed.
That is what online evaluation is for. You A/B test ranking changes against real behavior — click-through, course starts, and the one that actually matters for an LMS, downstream completions. The trap, and the reason so many recommenders quietly get worse, is optimizing a proxy: a ranking that maximizes clicks by surfacing sensational-looking courses but lowers completions has made discovery worse while the click dashboard says better. This is the recsys version of every metric-gaming story — the system optimizes exactly what you measured, so measure the thing you actually want. There is also a feedback loop to respect: a recommender that only ever shows popular courses makes them more popular and starves everything else of the exposure it needs to prove itself, so production systems deliberately inject a little exploration (occasionally surface promising-but-unproven items) to avoid collapsing into a rich-get-richer monoculture. Tie evaluation to completions, guard against proxy-gaming, and leave room to explore, and the metrics stay honest.
| Metric | Question it answers | Watch out for |
|---|---|---|
| precision@k | Are the top results relevant? | Ignores anything past position k |
| recall | Did we surface the relevant items at all? | High recall can mean low precision |
| NDCG | Are the best results ranked highest? | Needs graded relevance labels |
| Online A/B (completions) | Did the change help real learners finish? | Don’t optimize clicks over completions |
A tenancy trap worth naming: isolation outside Postgres
One architectural consequence of moving search into its own datastore deserves a callout, because it silently undoes a guarantee earlier parts took for granted. The Postgres tables of Parts 2–5 were isolated automatically: Part 2’s Hibernate @TenantId filtered every query and Row-Level Security backed it at the database. A search index has neither. The moment catalog data leaves Postgres for OpenSearch, that automatic isolation is gone, and a forgotten tenant filter in a search query is a cross-tenant data leak — one organization seeing another’s private courses. Scholr re-earns the guarantee by hand: every indexed document carries its tenantId, and every search filters on the current tenant explicitly. The lesson generalizes to every non-Postgres store you add — a cache, a search index, a vector database: isolation does not travel with the data; you re-implement it at each new datastore, deliberately.
The war story, resolved — and what we’d do differently
Scholr’s stale-index afternoon was the predictable result of treating search as a thing that periodically catches up to the truth. The fix was to make it a projection of the event stream — fresh within seconds of a catalog change — and to make structural rebuilds safe with alias-based zero-downtime reindexing, so a reindex is a non-event for learners instead of an outage. After it shipped, a catalog refresh propagated to search almost immediately, and a full reindex (which used to mean downtime) became a routine background operation nobody noticed.
What would we do differently? We would have driven the index from the event stream from the first version, rather than bolting on a nightly job and discovering its staleness in production — the stream was right there. We would have started with hybrid search instead of keyword-only, because retrofitting semantic search means re-embedding the entire catalog under load. And we would have built the tenant filter into the search layer on day one, not as a fix after a near-miss, because “isolation outside Postgres is automatic” is exactly the assumption that produces a breach. The thread, again: decide the hard property up front, encode it once, and prove it.
Get the code and run it
Everything above is in the companion repository, evolving the same codebase the series has built since Part 1. Each part has its own branch frozen at that lesson’s checkpoint, and main always holds the latest cumulative code.
# this part's exact code:
git clone https://github.com/muasif80/tutorial-lms-platform.git
cd tutorial-lms-platform
git checkout part-6
# the latest cumulative build is always on main:
git checkout mainVerify it the way the build does — keyword/semantic/hybrid ranking, content-based and cold-start recommendations, tenant-isolated search, and the zero-downtime alias swap all run under one command:
mvn verify # green = the three search modes, cold-start recs, and the zero-downtime reindex all holdWhere each idea in this article lives in the code:
- Keyword / semantic / hybrid search + ranking signals —
discovery/SearchService.java+discovery/SearchMode.java. - The embedding seam (a real model plugs in here) —
discovery/TextVectorizer.java. - The search-index port + zero-downtime alias reindex —
discovery/SearchIndex.java,InMemorySearchIndex.java, anddiscovery/IndexingService.java. - Content-based recommendations + cold-start fallback —
discovery/RecommendationService.java. - Hand-rolled tenant isolation outside Postgres — the
tenantIdfilter inInMemorySearchIndexandSearchService. - The proof —
DiscoverySearchTest.javaasserts the three modes, recommendations/cold-start, tenant isolation, and the alias swap.
Frequently asked questions
Full-text, semantic, or hybrid search for a course catalog?
Hybrid, for any real catalog. Keyword (BM25) search is precise and great for exact terms, codes, and acronyms but blind to synonyms; semantic (vector) search finds conceptually related results across different wording but can drift to related-but-wrong and needs an embedding model. Hybrid runs both, combines the scores, and reranks — you get the exactness of keywords and the recall of meaning. Start keyword-only only if you genuinely can’t run a vector layer yet, and plan to add it.
How do I keep my search index fresh without downtime?
Drive the index from your event stream so a catalog change upserts the affected document within seconds, instead of rebuilding nightly. For structural changes or full rebuilds, use alias-based zero-downtime reindexing: searches hit a stable alias that points at a physical index; you build a new physical index alongside the live one, fill it completely, then atomically repoint the alias. Readers never see a half-built index, and rollback is just pointing the alias back.
How do I recommend courses with no interaction history (cold start)?
Use content-based recommendations, which need only item content (embeddings), not behavior — “more like this course” works from day one. For a learner with no history and no seed course at all, fall back to a sensible non-personalized ranking such as the most popular, best-completed courses. That default beats an empty shelf and gathers the interaction signal that later lets collaborative filtering take over.
How do I add an AI tutor without it hallucinating?
Use retrieval-augmented generation grounded in the learner’s own course materials: retrieve the most relevant passages with the same embeddings that power semantic search, and instruct the model to answer only from those passages, with citations, and to say it doesn’t know when the materials don’t cover the question. Every answer should cite its source so a hallucination has nowhere to hide, and the tutor must refuse to answer graded assessment questions — it explains and points, it doesn’t take the exam.
Conclusion
Discovery is where an LMS turns a catalog into a path. We built search as a first-class system with keyword, semantic, and hybrid modes and domain-aware ranking; kept it fresh and rebuildable with an event-driven pipeline and zero-downtime alias swaps; answered the cold-start problem honestly with content-based recommendations and a popularity fallback; added an AI tutor grounded and cited so it helps without hallucinating; and re-earned tenant isolation the moment data left Postgres. Scholr’s stale-index afternoon — and the slow bleed of learners who couldn’t find or weren’t guided to the right course — is now designed out.
The full, tested implementation — the search modes, the recommender, and the zero-downtime reindex, all verified by a build that proves them — is on the part-6 branch of the companion repository. ⭐ Star it to follow the build. Next, in Part 7, we make the platform a business: payments, billing, and subscriptions — webhook idempotency, entitlements, dunning, and the tax and revenue edge cases that turn a feature into a liability.
