

Nine parts built features. This one builds trust — and trust is what separates a demo from a platform. Across the series we designed the domain, the data, video, assessments, the event backbone, discovery, billing, interoperability, and the experience layer. Each was correct in isolation. But “production-grade software” is not a sum of correct features; it is a separate property layered over all of them: the assurance that the system is secure, that a change won’t silently break it, that it survives a traffic spike and a region failure, that you can see what it’s doing when it misbehaves at 3 a.m., and that it doesn’t quietly bankrupt you. This capstone assembles the full reference architecture and earns the word “production” — security and compliance, a real test and CI/CD pipeline, resilience against cascading failure, observability and SLOs, multi-region disaster recovery, and cost control — and then shows you exactly how to deploy and run the whole thing.
The capstone war story is the one every platform eventually lives through: a cascading failure. One Tuesday a downstream dependency — the search cluster — slowed from 20ms to 2s. Scholr’s request threads, waiting on it, piled up; the thread pool exhausted; new requests queued; the app’s health check (which itself touched the database, now starved of connections) began to fail; the load balancer, seeing unhealthy nodes, pulled them out of rotation; and the surviving nodes inherited the full traffic of the dead ones and fell in turn, like dominoes. A single slow dependency took down the entire platform in ninety seconds, and nothing was “broken” — every component did exactly what it was coded to do. Containing this class of failure is what most of this part is about, and the patterns that prevent it are the difference between a system that degrades and one that collapses.
Security and compliance, in depth
Security is not a feature you add; it is a property you maintain, and for an LMS holding student records the stakes are legal as well as reputational. Start with the OWASP Top 10 mapped to this system’s specific risks. Broken access control is the number-one risk and, for a multi-tenant platform, takes a particularly dangerous form: IDOR across tenants — a request that swaps an id and reads another organization’s data. This is exactly why Part 2 enforced isolation in two independent layers (Hibernate’s @TenantId and PostgreSQL Row-Level Security): defense in depth means a single forgotten check is not a breach. Injection and XSS are acute here because an LMS runs untrusted content — user submissions, and worse, the third-party SCORM packages from Part 8, which is why that part sandboxed them and hardened the XML parser against XXE. SSRF lurks anywhere the platform fetches a URL (an LTI launch, a webhook, a remote thumbnail).
Around the application sit the program-level controls that auditors and enterprise buyers require. Secrets management: credentials live in a vault (HashiCorp Vault, AWS/GCP Secrets Manager), never in code or an image — the .env file in the repo is a development convenience, and the comment in it says exactly that. Audit logging: every security-relevant action (a login, a permission change, a grade override, a data export) is recorded immutably, because “who did what, when” is the first question of any incident or compliance review. Data privacy: an LMS is subject to FERPA (US student records), GDPR (EU), and contractual DPAs, which demand data-subject rights, retention limits, and the crypto-shredding deletion approach Part 5 built into the event pipeline. And supply-chain security: dependency scanning in CI, a generated SBOM (software bill of materials), and pinned, reviewed dependencies — because most modern breaches enter through a library, not your own code. For enterprise sales this all rolls up into a path to SOC 2, the report that turns “trust us” into “here’s the audited evidence.”

A testing strategy that lets you ship without fear
You cannot operate what you cannot change safely, and you cannot change safely without tests you trust. The shape is the classic test pyramid: many fast unit tests, fewer integration tests, fewer still end-to-end tests — inverting it (mostly slow, brittle e2e tests) is how teams end up afraid to deploy. This series’ companion code lives the pyramid: pure unit tests for the deterministic grader and the conflict-free merge, integration tests on a real persistence stack for tenant isolation and the idempotent writes, and ArchUnit tests that fail the build if a module reaches into another’s internals — architecture enforced as a test.
| Layer | Tests | Speed | Catches |
|---|---|---|---|
| Unit (most) | Pure logic — grading, merge rules | Milliseconds | Logic errors |
| Integration | DB, tenant isolation, idempotency | Seconds | Wiring, persistence, isolation |
| Contract | API shape vs the frontend’s expectations | Seconds | Front/back drift |
| End-to-end (fewest) | Critical user journeys | Minutes | Whole-flow regressions |
| Load | Find the real ceiling before prod does | Minutes–hours | Capacity, the cascade |
Two disciplines matter beyond the pyramid. For a multi-tenant platform, testing isolation itself is a first-class concern — there must be a test that creates two tenants and proves one cannot read the other’s data, which this codebase has at every layer. And flaky tests are treated as failures: a test that passes 95% of the time erodes trust in the entire suite until nobody believes a red build, so a flaky test is quarantined and fixed, not re-run until green. A test suite is only as valuable as your willingness to block a release on it.
CI/CD: the paved road to production
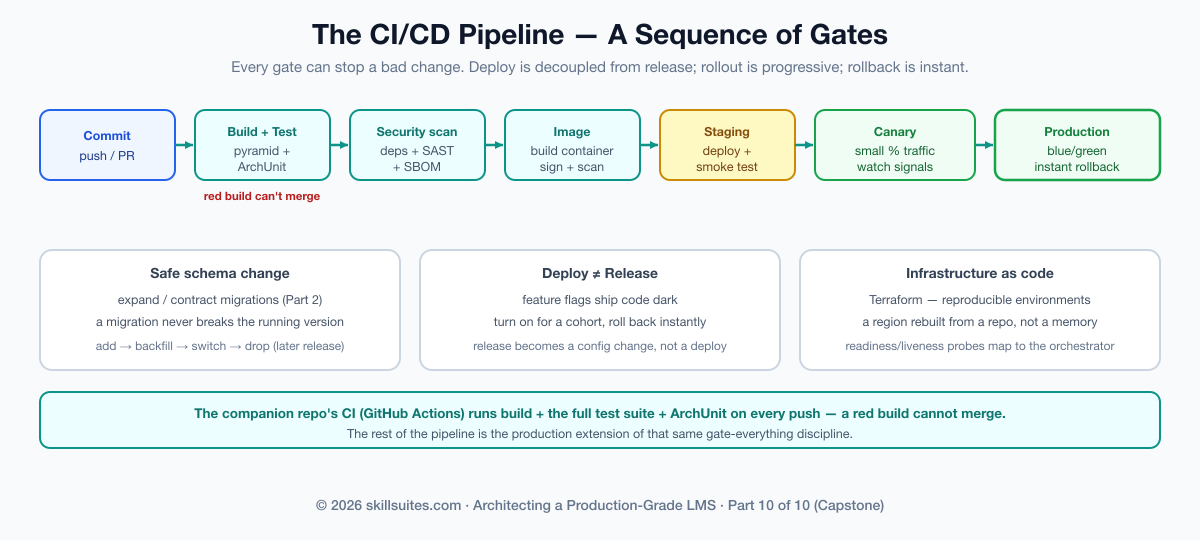
Continuous integration and delivery is the automation that turns “it works on my machine” into “it’s safely in production,” and it is a sequence of gates, each of which can stop a bad change. A commit triggers: build → test (the whole pyramid) → security scans (dependency + SAST) → build a container image → deploy to staging → smoke test → progressive rollout to production. The companion repo’s CI runs the build, the full test suite, and the architecture checks on every push — a red build cannot merge. The rollout is where caution lives: rather than flipping all traffic at once, a canary sends a small percentage to the new version and watches the golden signals before proceeding, and blue/green keeps the old version live for an instant rollback. Schema changes ride the expand/contract pattern from Part 2 so a migration never breaks the running version, and feature flags decouple deploy from release, letting you ship code dark and turn it on for a cohort. All of it sits on infrastructure-as-code (Terraform) so environments are reproducible and a region can be rebuilt from a repository rather than a memory.
Resilience: containing the cascade
Now back to the Tuesday outage, because its prevention is a small set of patterns that every distributed system needs and that the idempotency built throughout this series finally pays off. The cascade had a precise anatomy — a slow dependency, unbounded waiting, resource exhaustion, health-check failure, and load-shedding onto fewer and fewer nodes — and each link is broken by a specific pattern.
| Pattern | What it does | Breaks which link |
|---|---|---|
| Timeouts | Cap how long any call may wait | “Unbounded waiting” — no thread waits 2s on a 20ms call |
| Retries + backoff & jitter | Retry transient failures, spread out | Prevents a synchronized retry storm |
| Circuit breaker | Stop calling a failing dependency; fail fast | “Resource exhaustion” — sheds load off the sick service |
| Bulkheads | Isolate resource pools per dependency | One slow dependency can’t drown the others |
| Graceful degradation | Serve a reduced experience, not an error | Search down ≠ platform down |
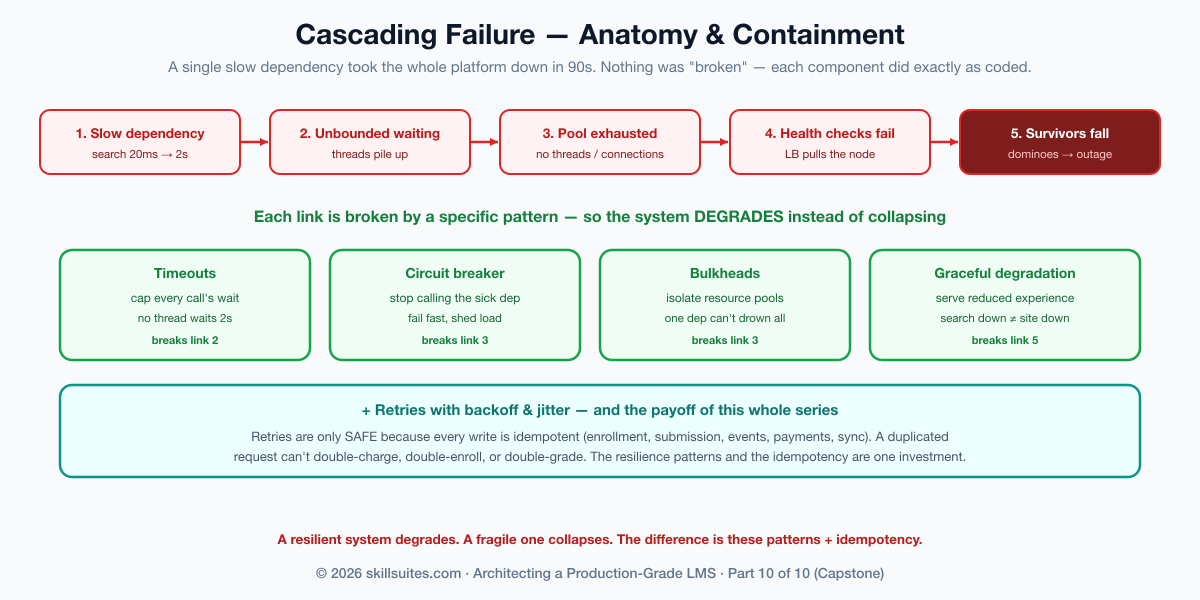
The throughline: a resilient system degrades instead of collapsing. When search slows, a circuit breaker trips and the catalog falls back to a cached or simpler listing; the learner notices a less-smart search, not an outage. And the idempotency this series insisted on everywhere — enrollment, submission, events, payments, sync — is what makes the most important resilience pattern, the retry, safe: you can only retry freely if a duplicated request can’t double-charge, double-enroll, or double-grade. The patterns that prevent cascading failure and the idempotency that enables safe retries are the same investment, finally compounding.
Caching and its dragons: the thundering herd
Caching is the highest-leverage performance tool and the source of some of the nastiest production incidents, the worst being the cache stampede (thundering herd). A popular item — a celebrity instructor’s course page — is cached; the cache entry expires; and in the same instant a thousand concurrent requests all miss, all hit the database to recompute the same value, and the database falls over under a self-inflicted spike. The expiry that was supposed to protect the database became the weapon against it. The mitigations are well understood and worth combining: single-flight (request coalescing) so only one request recomputes while the rest wait for its result; jittered TTLs so a million entries don’t expire on the same tick; stale-while-revalidate so an expired entry is served (slightly stale) while one request refreshes it in the background; and negative caching so a flood of requests for something that doesn’t exist doesn’t hammer the database with the same failing lookup. Caching is not “add Redis and forget”; it is a set of deliberate choices about what happens at the exact moment an entry expires.
Hot partitions, rate limiting, and fairness
Multi-tenancy and popularity both create hot partitions — the celebrity course, the giant enterprise tenant, the one learner running a script — that concentrate load on a slice of the system and can starve everyone else, the noisy-neighbor problem this series first met in Part 3. The defense is rate limiting with fairness built in: a per-tenant (and per-user) token bucket caps any one actor’s consumption, so a single tenant’s traffic spike or a runaway client throttles itself rather than degrading the platform. Fairness is the operative word — a global rate limit protects the system but lets a big tenant crowd out a small one; a per-tenant limit protects tenants from each other, which is the actual guarantee a multi-tenant platform sells. Surfacing rate-limit state in response headers lets well-behaved clients back off politely, turning enforcement into cooperation.
Observability and SLOs: knowing before your users do
You cannot operate what you cannot see, and observability is the discipline of being able to ask new questions about your running system without shipping new code. Instrument the three pillars — metrics (cheap, aggregate), logs (detailed, expensive), and traces (a request’s path across services) — through a vendor-neutral standard, OpenTelemetry, so you are not locked into one backend. Watch the four golden signals: latency, traffic, errors, and saturation — the small set that, together, tell you almost everything about a service’s health.
| Golden signal | Question it answers | Alert when |
|---|---|---|
| Latency | How slow are requests? | p99 breaches the SLO |
| Traffic | How much demand? | Anomalous spike/drop |
| Errors | How often does it fail? | Error rate burns the budget |
| Saturation | How full are the resources? | Approaching a limit (CPU, pool, queue) |
Above the metrics sit SLOs (Service Level Objectives) and error budgets, the SRE idea that reframes reliability as a number you manage rather than a vibe. An SLO (“99.9% of enrollments succeed in under 300ms”) defines a target; the error budget is the small allowed failure (0.1%); and the budget governs decisions — burn it slowly and you ship features freely, burn it fast and you freeze features to fix reliability. The corollary is alerting that doesn’t cry wolf: page a human only on symptoms that matter to users and threaten the budget, not on every transient blip, because an on-call engineer who is woken by noise will eventually sleep through the real fire. Health probes belong here too — the readiness and liveness endpoints this part wires into the app let an orchestrator restart a wedged instance and route traffic only to ready ones, automating the first response.
Multi-region and disaster recovery
A single region will, eventually, fail — a fiber cut, a bad deploy, a cloud-provider outage — and your answer to that is defined by two numbers. RPO (Recovery Point Objective) is how much data you can afford to lose (the gap since the last durable replica); RTO (Recovery Time Objective) is how long you can afford to be down. These numbers, agreed with the business, dictate the architecture. Active-passive keeps a warm standby region with replicated data and fails over on disaster — simpler and cheaper, with a real RTO measured in minutes. Active-active serves from multiple regions simultaneously — near-zero RTO and better latency, but far harder because now data consistency spans regions. Data residency complicates both: GDPR and similar laws may require an EU tenant’s data to stay in the EU, which a multi-tenant platform satisfies by pinning a tenant’s data to a region. And the rule that separates teams who have a DR plan from teams who have DR: you must actually run the failover drill. An untested backup is a hope, not a recovery plan; the drill is where you discover the restore script is broken before the outage, not during it.
FinOps: where the money leaks
A platform that works but loses money on every active learner is not production-grade either, and an LMS has a few characteristic leaks worth watching. The largest is usually video egress — serving course video is bandwidth-intensive, and the Part 3 CDN architecture exists as much for cost as for performance, because origin egress at scale is the bill that surprises founders. Then come the quieter leaks: idle compute (over-provisioned nodes running at 15% utilization — the case for the autoscaling above), an over-provisioned database (paying for peak capacity 24/7), and, ironically, the observability bill itself, since logs and high-cardinality metrics can cost more than the service they monitor. The metric that ties it together is cost per active learner: tracked over time, it tells you whether the platform’s unit economics improve or decay as it grows, which is the difference between a business and an expensive hobby. FinOps is not penny-pinching; it is keeping the system’s cost curve below its value curve.
How to deploy and run the whole system
All of this culminates in a system you can actually run, and the companion repository ships a complete, reproducible deployment. The application is a stateless modular monolith that reads all of its configuration from the environment (12-factor) and owns no data itself; PostgreSQL is the single stateful service, and Flyway runs every migration (V1 through V6) automatically on startup, so the full schema — all twelve bounded contexts, with Row-Level Security — is created for you. The entire stack comes up with one command:
# 1. clone and enter the repo
git clone https://github.com/muasif80/tutorial-lms-platform.git
cd tutorial-lms-platform
# 2. (optional) set secrets — sensible defaults work out of the box
cp .env.example .env # edit DB_PASSWORD etc. for anything real
# 3. build the image and start Postgres + the app together
docker compose up -d --build
# 4. the app is healthy only once the DB is connected and migrations have applied
curl localhost:8080/actuator/health # {"status":"UP"}
curl localhost:8080/contexts # the live bounded contextsThe committed docker-compose.yml wires the two services correctly: the app depends_on the database’s health check, so it never races a database that isn’t ready; Postgres data lives in a named volume so it survives restarts; and the app exposes a readiness probe (the Spring Boot Actuator endpoint this part added) that reports healthy only when the database is connected and Flyway has finished — exactly the signal an orchestrator needs. The container itself is hardened: a multi-stage build produces a small JRE image, it runs as a non-root user, and it carries a HEALTHCHECK. Once it’s up, you can drive the live API — create a tenant, then act inside it with the X-Tenant-Id header, and watch the tenant isolation hold:
# create a tenant (the organization registry is global)
curl -XPOST localhost:8080/api/organizations
-H 'Content-Type: application/json' -d '{"name":"Acme University"}'
# -> { "id": "<TENANT>", "name": "Acme University" }
# act INSIDE that tenant — the header scopes every query
curl -XPOST localhost:8080/api/courses
-H "X-Tenant-Id: <TENANT>" -H 'Content-Type: application/json'
-d '{"title":"Intro to Astrophysics"}'
# a different tenant sees none of it — @TenantId + Row-Level Security, live
curl localhost:8080/api/courses -H "X-Tenant-Id: <OTHER-TENANT>" # -> []From here the path to a cloud production deployment is a change of substrate, not of architecture: the same image runs on Kubernetes (the readiness and liveness probes map straight to the orchestrator’s), behind a load balancer, with the app scaled horizontally (docker compose up -d --scale app=3 locally, a Deployment with an HPA in production) and PostgreSQL swapped for a managed, replicated database. Because the app is stateless and every write is idempotent and tenant-scoped, running many instances is safe by construction — the property the whole series was quietly building toward.
mvn verify # the full proof: 44 tests — tenant isolation, idempotency,
# the seat invariant, grading, fan-out, outbox, billing, sync — all greenThe assembled reference architecture, and the full tech stack
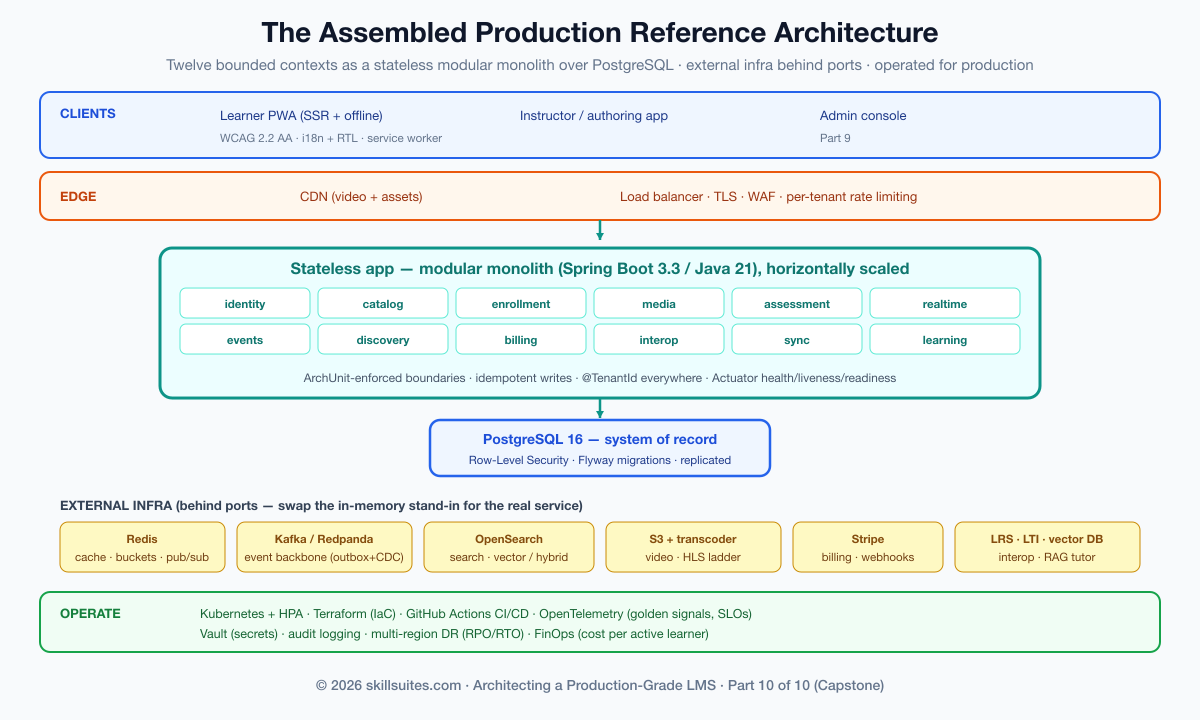
Stepping back, the complete platform is a modular monolith of twelve bounded contexts over PostgreSQL, fronted by a typed API and a three-surface frontend, fed by an event backbone, integrated with the institutional ecosystem, and operated behind the resilience, observability, and deployment machinery of this capstone. The reference architecture diagram below shows how the pieces fit; the table that follows catalogs every third-party and open-source technology the design calls for, and — importantly — distinguishes what the companion code actually implements from what it models behind a seam (so a real production build knows exactly what to wire up).
| Layer | Technology | Role | In the companion code |
|---|---|---|---|
| Language / runtime | Java 21 | Application language | ✅ Implemented |
| Framework | Spring Boot 3.3 (Web, Data JPA, Actuator) | App framework, REST, health probes | ✅ Implemented |
| Persistence | Hibernate / JPA, @TenantId |
ORM + automatic tenant filtering | ✅ Implemented |
| Database | PostgreSQL 16 (+ Row-Level Security) | System of record, tenant isolation | ✅ Implemented |
| Migrations | Flyway | Versioned schema (V1–V6) | ✅ Implemented |
| Build / test | Maven, JUnit 5, ArchUnit, H2 | Build, tests, module-boundary enforcement | ✅ Implemented |
| Container / run | Docker + Docker Compose | Build & one-command deployment | ✅ Implemented |
| CI | GitHub Actions | Build + test gate on every push | ✅ Implemented |
| Cache | Redis | Hot-path cache, rate-limit buckets, presence | 🔶 Designed (Part 4/10) |
| Event streaming | Kafka / Redpanda (+ Debezium CDC) | Event backbone behind the outbox | 🔶 Seam (EventPublisher, Part 5) |
| Search | OpenSearch / Elasticsearch | Catalog search + vector/hybrid | 🔶 Seam (SearchIndex, Part 6) |
| Media | S3-compatible storage + transcoder + CDN, HLS | Video at scale | 🔶 Seam (SignedUrlIssuer, Part 3) |
| Realtime | WebSocket tier + Redis pub/sub | Live classes, chat, presence | 🔶 Seam (MessageBroker, Part 4) |
| Payments | Stripe (Billing, Checkout, webhooks) | Subscriptions, entitlements | 🔶 Seam (PaymentGateway, Part 7) |
| Interop | LTI 1.3, SCORM, xAPI + an LRS | Institutional integration | 🔶 Implemented + seams (Part 8) |
| Embeddings / AI | Embedding model + vector DB; an LLM (e.g. Claude) for tutoring | Semantic search, RAG tutor | 🔶 Seam (TextVectorizer, Part 6) |
| Frontend | Next.js / Nuxt (SSR), a design system, PWA + service worker | Learner/instructor/admin surfaces | 🔶 Designed (Part 9) |
| Secrets | Vault / cloud Secrets Manager | Credential management | 🔶 Designed (env in dev) |
| Observability | OpenTelemetry + a metrics/log/trace backend | Golden signals, SLOs, tracing | 🔶 Designed (Actuator implemented) |
| Orchestration / IaC | Kubernetes (HPA) + Terraform; CDN | Scaling, reproducible infra | 🔶 Designed (probes + compose ready) |
The pattern in that last column is the deliberate design of the whole series: the core — the domain, multi-tenancy, the data model, idempotency, the bounded contexts, the deployable artifact — is fully implemented and tested, while the heavy external infrastructure (Kafka, OpenSearch, Stripe, the CDN, the LLM) is isolated behind a small port so the code runs and is verifiable without it, and a production build swaps each in-memory stand-in for the real service with no change above the seam. That is what makes this a reference architecture you can both run today and grow into production, rather than a slide deck.
Retrospective: the whole series, and what we’d do differently
Ten parts traced one fictional platform, Scholr, from an idea to production grade, and a single discipline runs through every one: decide the hard property up front, encode it in one place, and prove it. Multi-tenancy in two layers so a leak is structurally impossible. Idempotency on every state-changing write so a retry is always safe — a decision that paid off again and again, in enrollment, submissions, events, payments, SCORM completions, and offline sync, and that finally made the resilience patterns of this capstone work. Bounded contexts enforced by the build so the monolith stayed modular. Reliability, accessibility, and conflict-free merge designed in rather than retrofitted. If we did it again, we would reach for these properties even earlier, because every one was cheaper to build in than to bolt on — which is the most expensive lesson in software, learned in advance here.
And there is a meta-point worth stating plainly, because it is why this series exists. The engine, the architecture, and the war stories are the asset. Building a production-grade system in the open — and writing down the decisions, the trade-offs, and the failures — turns engineering into a durable, compounding body of work that teaches, attracts, and credentials far beyond any single product. The code is MIT-licensed and runnable; the knowledge around it is the thing of lasting value.
Frequently asked questions
How do I prevent a cache stampede / thundering herd?
Combine four techniques. Use single-flight (request coalescing) so that when a hot cache entry expires, only one request recomputes the value while the rest wait for its result instead of all hitting the database. Add jitter to TTLs so many entries don’t expire on the same tick. Use stale-while-revalidate to serve a slightly stale value while one request refreshes it in the background. And use negative caching so repeated requests for something that doesn’t exist don’t hammer the database. The stampede happens at the instant of expiry, so the fix is about controlling what happens at that moment, not just adding a cache.
What resilience patterns actually prevent cascading failures?
Timeouts (so no call waits unboundedly on a slow dependency), retries with exponential backoff and jitter (so retries don’t become a synchronized storm), circuit breakers (stop calling a failing dependency and fail fast, shedding load), bulkheads (isolate resource pools so one slow dependency can’t exhaust the threads the others need), and graceful degradation (serve a reduced experience rather than an error). Together they make a system degrade instead of collapse. Idempotent writes are the enabler that makes the retry pattern safe, because a duplicated request can’t cause double effects.
What does a real CI/CD and test pipeline for an LMS look like?
A test pyramid — many unit tests, fewer integration tests, fewest end-to-end tests, plus contract and load tests — with a specific test that proves multi-tenant isolation, and a zero-tolerance policy for flaky tests. The pipeline gates every change: build, run the whole test suite and architecture checks, run dependency and static security scans, build a container image, deploy to staging and smoke-test, then roll out progressively with a canary and blue/green for instant rollback. Schema changes use expand/contract so a migration never breaks the running version, feature flags separate deploy from release, and everything sits on infrastructure-as-code.
Where do LMS cloud costs leak the most?
Usually video egress first — serving course video is bandwidth-heavy, which is why a CDN is a cost decision as much as a performance one. Then idle or over-provisioned compute (nodes running at low utilization, which autoscaling fixes), an over-provisioned database paying for peak capacity around the clock, and the observability bill itself, since logs and high-cardinality metrics can cost more than the service they watch. Track cost per active learner over time as the single number that tells you whether your unit economics improve or decay as you grow.
Conclusion: production-grade, and assembled
Production-grade is not a feature; it is the trust that a system is secure, won’t break on change, survives spikes and region failures, can be seen into when it misbehaves, and doesn’t bankrupt you. We earned it here: OWASP-aware security and a compliance program; a test pyramid and a gated CI/CD pipeline; resilience patterns that contain the cascade, enabled by the idempotency the whole series built; caching that survives the thundering herd; per-tenant rate limiting for fairness; observability with golden signals and SLOs; multi-region DR with tested failover; and FinOps to keep cost below value. And it all runs — one docker compose up brings the entire twelve-context, multi-tenant platform to life, the same image that scales to Kubernetes in production. Scholr is, at last, a platform rather than a demo.
That completes the journey: ten parts, one coherent reference architecture, every part with runnable, tested code on its own branch and the whole cumulative system on main. ⭐ Star the repository, clone it, run it, and take it apart — it is built to be learned from. If this systems-design approach resonates, our production engineering playbook applies the same discipline to shipping AI. Thank you for building this platform with us, from the first design decision to production.
The series continues. This part is the capstone of the architecture arc (Parts 1–10) — the backend, productionized. From here the series builds a working platform on top of it: Part 11 — login, RBAC & a server-rendered UI, then the instructor (Part 12), student (Part 13), and admin (Part 14) workspaces, and rich lesson authoring (Part 15) — a multi-role LMS you can actually log into and use.
