

Instructor course authoring is where a learning platform stops being a database with a login screen and starts being a product an instructor can actually use. In Part 11 we gave the LMS real authentication, enforced role-based access control, and a server-rendered UI that lands each role on its own dashboard. The dashboards were real, but the instructor’s tools behind them were still placeholders. Part 12 fills that in: a working instructor workspace where an instructor can create a course, author its lessons, move it through a draft→publish lifecycle, and see exactly who is enrolled in each cohort — all server-rendered with Spring Boot and Thymeleaf, all tenant-scoped, and all verified by the same CI that has guarded every part of this series.
This is the second instalment of the “working platform” arc that extends the Architecting a Production-Grade LMS series from a reference backend into something you can run, log into, and operate. By the end of this part the instructor role is no longer a sketch: it authors content end to end, and that content shows up in the catalogue the student will browse in Part 13.
Where Part 12 sits in the series
The first ten parts built the backend — multi-tenant persistence, media, assessments, an events pipeline, search, billing, interoperability, offline sync, and a production deployment. Part 11 put a face on it. Parts 12 through 14 build out the three role workspaces until the platform supports a complete end-to-end flow:
| Part | Role | What becomes real |
|---|---|---|
| 11 | All roles | Login, RBAC, tenant-from-identity, role dashboards, admin enrol flow |
| 12 | Instructor | Author courses & lessons, draft→publish lifecycle, cohort rosters |
| 13 | Student | Catalogue → enrol → course player → assessment → progress |
| 14 | Admin | Console depth: billing view, reports, deeper user management |
Each part ships as a branch on the companion repository and a live, CI-verified deployment, so the code in this article is the code that runs.

What we inherit from Part 11
Three Part 11 mechanisms do the heavy lifting here, and the instructor workspace is built directly on top of them:
- Authentication. Spring Security form login authenticates against a global, tenant-less
Credential(BCrypt-hashed). The instructor signs in at/loginwith[email protected]. - Enforced RBAC. The security config gates
/instructor/**toROLE_INSTRUCTOR. A logged-in student who pokes at an instructor URL gets a403, not a redirect — the boundary is real. - Tenant from the identity. A servlet filter,
TenantPrincipalFilter, reads the authenticated principal and pins the current tenant before any controller runs. This is the single most important inheritance: it means none of the code in this article ever passes a tenant id around. The instructor’s organisation is implied by who is logged in, and every query is filtered automatically.
That last point is what keeps the instructor controller honest. There is no tenantId path variable, no hidden form field, no trusted header. An instructor at Acme University literally cannot construct a URL that reaches another university’s courses, because the tenant is resolved from the session, not the request payload.
The missing model: lessons
The backend already had Course and Cohort aggregates from Part 2, but a course with no lessons isn’t something you can author. So Part 12’s one new entity is the Lesson — the smallest model that makes course authoring real: a title, an ordinal position, and a body of text.
@Entity
@Table(name = "lessons")
public class Lesson {
@Id
private UUID id;
@TenantId
@Column(name = "tenant_id", nullable = false, updatable = false)
private UUID tenantId;
@Column(name = "course_id", nullable = false, updatable = false)
private UUID courseId;
@Column(nullable = false)
private String title;
@Column(nullable = false)
private int position;
@Column(length = 4000)
private String body;
public static Lesson of(UUID courseId, String title, int position, String body) {
return new Lesson(UUID.randomUUID(), courseId, title, position, body);
}
// accessors omitted
}Two design rules from earlier parts carry straight through. First, the @TenantId discriminator: Hibernate stamps every insert with the current tenant and filters every read by it, so a lesson can never leak across organisations. Second, the cross-aggregate reference is by id — courseId is a plain UUID, not a JPA @ManyToOne association. A lesson points at its course the way a foreign key does, but the object graph stays small and the module boundary stays hard. (Why that rule matters bites us later in this very article, in the roster.)
The matching Flyway migration mirrors every other table in the system — a tenant_id column, an index on it, and PostgreSQL Row-Level Security so the database itself refuses a cross-tenant read even if the application forgets the filter:
-- V8__lessons.sql
CREATE TABLE lessons (
id UUID PRIMARY KEY,
tenant_id UUID NOT NULL REFERENCES organizations(id),
course_id UUID NOT NULL REFERENCES courses(id),
title TEXT NOT NULL,
position INT NOT NULL,
body VARCHAR(4000)
);
CREATE INDEX idx_lessons_tenant ON lessons(tenant_id);
CREATE INDEX idx_lessons_course ON lessons(course_id);
ALTER TABLE lessons ENABLE ROW LEVEL SECURITY;
CREATE POLICY lessons_tenant_isolation ON lessons
USING (tenant_id = current_setting('app.tenant_id')::uuid);This is the eighth migration in the series and it looks exactly like the first seven. That sameness is the point: tenant isolation is a pattern you apply mechanically to every new table, not a decision you re-litigate. Defence in depth means the app layer (@TenantId) and the data layer (RLS) each enforce isolation independently, so a bug in one is caught by the other.
Why a plain text body, for now
A real LMS lesson is rarely just text — it’s video, embedded quizzes, slides, code sandboxes, downloadable resources. So why model the body as a single VARCHAR(4000)? Because the goal of this part is to make authoring real, not to model every content type, and a typed block system is a large feature in its own right. The honest move is to ship the smallest model that proves the flow end to end — an instructor can create, order, and publish lessons that a student will read — and to leave an obvious seam where richer content slots in later.
That seam is the Lesson entity itself. When typed blocks arrive (a List<LessonBlock> with subtypes for video, quiz, and embed, exactly as Part 9’s authoring discussion sketches), they hang off this aggregate without disturbing the controller, the publish lifecycle, or the tenant model — all of which are content-agnostic. Crucially, the media for those blocks already exists: Part 3 built the entire video pipeline (direct-to-storage upload, off-request transcoding, signed CDN playback). A video lesson is just a Lesson whose body references a VideoAsset by id — the same by-id discipline, one more time. Building the text version first isn’t cutting a corner; it’s sequencing the work so each layer rests on a finished one.
Authoring: the service layer
All of the instructor’s write operations go through CatalogService, which now owns both courses and lessons. Every method is a short, transactional, tenant-scoped operation:
@Service
public class CatalogService {
private final CourseRepository courses;
private final LessonRepository lessons;
@Transactional
public Course createCourse(String title) {
return courses.save(Course.create(title)); // starts as DRAFT
}
@Transactional
public Course publish(UUID courseId) {
Course course = courses.findById(courseId)
.orElseThrow(() -> new IllegalArgumentException("course not found: " + courseId));
course.publish(); // guarded state transition
return courses.save(course);
}
@Transactional
public Lesson addLesson(UUID courseId, String title, String body) {
int next = (int) lessons.countByCourseId(courseId) + 1;
return lessons.save(Lesson.of(courseId, title, next, body));
}
@Transactional(readOnly = true)
public List<Lesson> lessons(UUID courseId) {
return lessons.findByCourseIdOrderByPositionAsc(courseId);
}
}The two queries behind these methods live in a Spring Data repository, and they’re worth a look because they show how little code tenant-safety actually costs once the pattern is in place:
public interface LessonRepository extends JpaRepository<Lesson, UUID> {
/** A course's lessons in author-defined order. */
List<Lesson> findByCourseIdOrderByPositionAsc(UUID courseId);
long countByCourseId(UUID courseId);
}Neither method mentions the tenant. That isn’t an oversight — it’s the whole design. Hibernate’s @TenantId on the Lesson entity rewrites every query generated from this interface to include AND tenant_id = ?, filled from the current tenant the filter pinned at login. So findByCourseIdOrderByPositionAsc returns the lessons of this tenant’s copy of that course, and a malicious courseId belonging to another organisation simply matches nothing. The derived-query method names read like English (“find by course id, order by position ascending”) and Spring Data writes the SQL; the isolation is added underneath, uniformly, by the framework. You author the intent; the platform enforces the boundary.
A few more decisions are worth calling out, because each is a small lesson in building something real rather than a demo.
Position is computed on the server, one-based
When the instructor adds a lesson, its position is countByCourseId(courseId) + 1 — the next slot, computed from what’s already there, numbered from one so it reads naturally in the UI (“Lesson 1, Lesson 2”). The client never sends a position. That’s not laziness; it’s the same principle that runs through the whole series: the server owns ordering and state, the client only expresses intent. A client that could set its own position could create two “Lesson 1″s or leave gaps. By deriving it, the workspace stays consistent no matter what the form posts.
Publishing is a guarded transition, not a flag flip
It is tempting to make “publish” a checkbox — course.setPublished(true). We don’t. publish() lives on the Course aggregate as a method, and the service loads the course, calls the transition, and saves it back inside one transaction. The aggregate decides whether the transition is legal; the controller can’t reach in and set a boolean. Today the rule is simple (a draft becomes published, and publishing again is a harmless no-op — it’s idempotent), but the shape is what matters: when Part 14 adds “a course needs at least one lesson before it can go live,” that rule has exactly one place to live. State machines guarded inside the aggregate have been the spine of this series — the enrolment seat invariant in Part 2, the attempt lifecycle in Part 4, the subscription status in Part 7 — and course publication is the same idea applied to content.
The difference between the two approaches isn’t academic; it shows up the first time a second rule appears:
| Public boolean setter | Guarded aggregate transition | |
|---|---|---|
| Where the rule lives | Scattered across every caller that flips the flag | One method on the aggregate |
| Adding “needs a lesson first” | Find and fix every call site; miss one and you have a bug | Edit publish(); every caller is protected at once |
| Illegal transition (e.g. re-publishing) | Silently allowed unless each caller checks | Defined once — here, an idempotent no-op |
| Auditing / events on publish | Easy to forget on one path | Natural single hook point |
| Reasoning about state | Any code can put the course in any state | State only changes through named, legal moves |
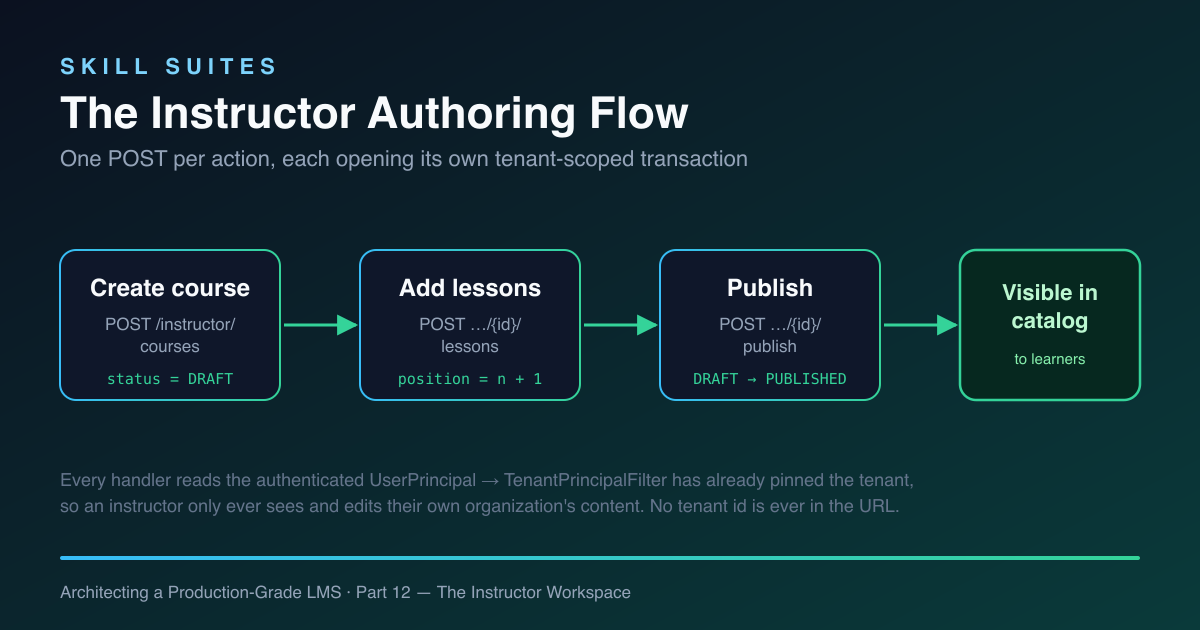
The instructor controller
The UI is a thin Spring MVC @Controller. It has no business logic of its own — it reads the principal, calls the service, and picks a template (or a redirect). Here is the whole authoring surface:
@Controller
public class InstructorController {
private final CatalogService catalog;
private final EnrollmentService enrollment;
private final IdentityService identity;
@GetMapping("/instructor/courses")
public String courses(@AuthenticationPrincipal UserPrincipal p, Model model) {
principal(model, p);
List<CourseRow> rows = new ArrayList<>();
for (Course c : catalog.allCourses()) {
rows.add(new CourseRow(c.id(), c.title(), c.isPublished(), catalog.lessonCount(c.id())));
}
model.addAttribute("courses", rows);
return "instructor/courses";
}
@PostMapping("/instructor/courses")
public String createCourse(@RequestParam String title) {
catalog.createCourse(title.isBlank() ? "Untitled course" : title.trim());
return "redirect:/instructor/courses";
}
@PostMapping("/instructor/courses/{id}/lessons")
public String addLesson(@PathVariable UUID id, @RequestParam String title,
@RequestParam(required = false) String body) {
catalog.addLesson(id, title.isBlank() ? "Untitled lesson" : title.trim(),
body == null ? "" : body);
return "redirect:/instructor/courses/" + id;
}
@PostMapping("/instructor/courses/{id}/publish")
public String publish(@PathVariable UUID id) {
catalog.publish(id);
return "redirect:/instructor/courses/" + id + "?published";
}
}Three patterns here are doing real work.
@AuthenticationPrincipal — the tenant is implicit. The handler receives the logged-in UserPrincipal directly from Spring Security. We use it for the display name and role label, but notice what we don’t use it for: there is no tenant id anywhere in these signatures. The TenantPrincipalFilter already pinned the tenant from this same principal before the controller ran, so catalog.allCourses() returns this instructor’s organisation’s courses and nothing else. Tenant isolation isn’t something the controller remembers to do; it’s something it cannot avoid.
POST-redirect-GET on every mutation. Every @PostMapping returns a redirect: rather than rendering a page. This is the Post/Redirect/Get pattern, and it’s not a nicety — it’s what stops a browser refresh from re-submitting the form and creating a duplicate course or a duplicate lesson. The mutation happens once, the browser lands on a fresh GET, and a refresh just re-reads. For an authoring tool where a double-submit means duplicated content, PRG is the difference between “works” and “works until someone hits F5.”
A view model, not the entity. The courses list builds a small CourseRow record (id, title, published, lessons) instead of handing the JPA entity to the template. That keeps the lesson count — a separate query — alongside the course without forcing a lazy-loaded association, and it gives the template a stable, intention-revealing shape to render. The entity stays in the persistence layer where it belongs.
Why the tenant filter is invisible — and why that’s the point
It’s worth pausing on the one thing the instructor controller conspicuously never does: pass a tenant id. There is a subtle timing rule underneath that, learned the hard way earlier in this series, and Part 12 depends on it.
Hibernate resolves “who is the current tenant” once, when it opens the database session — not on each individual save or query. So for the tenant filter to apply correctly, the tenant has to be set before the transaction begins. In a web request that ordering is exactly what the TenantPrincipalFilter guarantees: it runs as a servlet filter, well before Spring MVC dispatches to the controller and long before any @Transactional service method opens a session. By the time CatalogService.addLesson starts its transaction, the tenant is already pinned, so the INSERT is stamped with the right tenant_id and every SELECT is filtered by it.
Get that ordering wrong — resolve the tenant after the session is open — and you get the most insidious class of multi-tenant bug: writes that land under the wrong tenant, or a foreign-key violation because the row was stamped with a tenant that doesn’t exist. (That exact failure bit the demo data seeder in an earlier part, when a single wrapping transaction opened the session before the tenant was set.) The lesson generalises: tenant context is a property of the session boundary, so it must be established at the request boundary. The instructor controller is safe precisely because it inherits that discipline from Part 11 and never tries to manage the tenant itself.
Anatomy of a request: from click to rendered page
It helps to trace one request end to end, because the instructor workspace is really a thin layer riding on machinery built across the whole series. When the instructor clicks My Courses, here is everything that happens before the page paints:
- Spring Security checks the session. No authentication → redirect to
/login. Authenticated but wrong role →403. The/instructor/**path requiresROLE_INSTRUCTOR, so a logged-in student is stopped here, at the edge, before any controller code runs. - The
TenantPrincipalFilterreads the authenticated principal and pins the current tenant for this request — before the session opens. - Spring MVC dispatches to
InstructorController.courses, injecting theUserPrincipal. - The controller calls
catalog.allCourses()and, per course,catalog.lessonCount(...), assembling a list ofCourseRowview models. - The service opens a transactional session; Hibernate applies the
@TenantIdfilter using the tenant pinned in step 2, so the SQL only ever touches this organisation’s rows. - Thymeleaf renders
instructor/courses.htmlserver-side, splicing in the shared shell fragment, and returns finished HTML.
Six layers, and the application code you actually wrote — steps 3 and 4 — is a dozen lines. Authentication, authorisation, tenant isolation, transactions, and the SQL filter are all inherited from earlier parts and applied automatically. That’s the dividend of building the boring foundations first: by Part 12, a new screen is mostly intent, because the guarantees are already load-bearing underneath it.
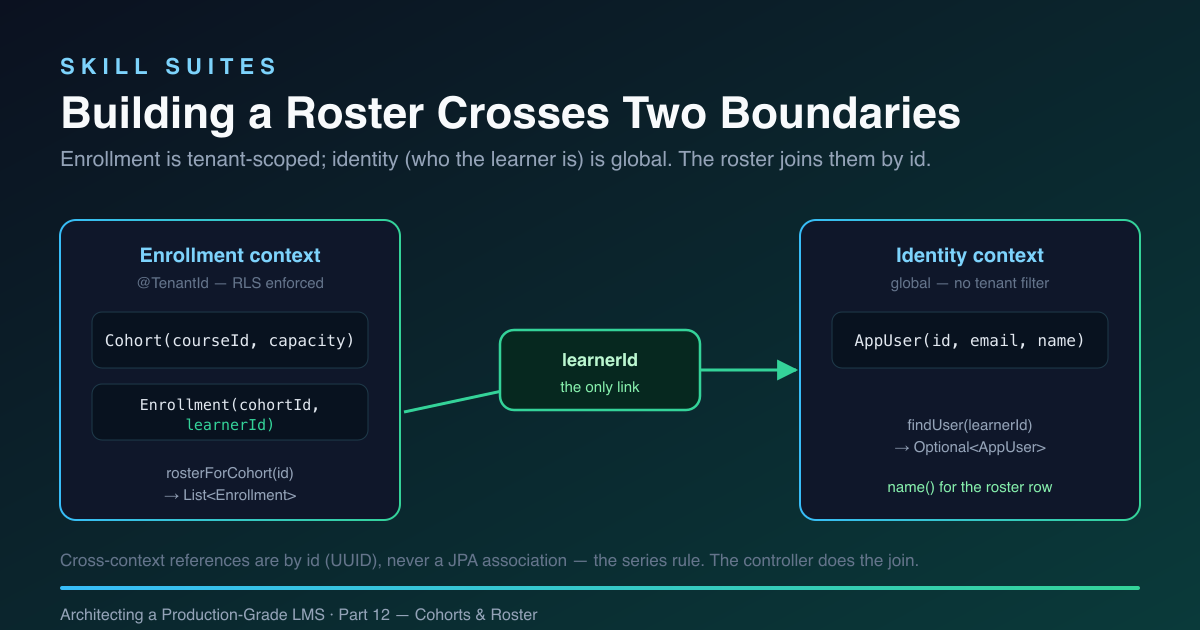
The roster: a join across two contexts
The cohorts-and-roster page is where the architecture earns its keep, and where the “reference by id” rule from Part 2 turns from dogma into a concrete decision you can feel.
An instructor wants to see, for each cohort of each of their courses, the names of the enrolled students. But the data lives in two different bounded contexts with two different isolation rules:
- Enrollment is tenant-scoped. A
Cohortbelongs to a course; anEnrollmentrecords that alearnerIdholds a seat in acohortId. Both carry@TenantIdand are protected by RLS. - Identity is global. An
AppUser(the person — id, email, name) is not tenant-scoped, because the same human can be a member of several organisations. There is no tenant filter on users at all.
So an Enrollment knows a learnerId, but not the learner’s name. To render “Maya Chen”, the controller has to cross from the tenant-scoped enrollment world into the global identity world — and the only thing that connects them is the id.
The Enrollment context exposes exactly two read methods for this, both read-only transactions because the roster never writes:
@Transactional(readOnly = true)
public List<Cohort> cohortsForCourse(UUID courseId) {
return cohorts.findByCourseId(courseId); // tenant-scoped
}
@Transactional(readOnly = true)
public List<Enrollment> rosterForCohort(UUID cohortId) {
return enrollments.findByCohortId(cohortId); // tenant-scoped
}And the Identity context exposes the one lookup that turns an id into a name — deliberately a separate call, not a join:
/** Look up a user by id (e.g. to render a roster of learner names). Users are global. */
public Optional<AppUser> findUser(UUID userId) {
return users.findById(userId);
}
@GetMapping({"/instructor/cohorts", "/instructor/grading"})
public String cohorts(@AuthenticationPrincipal UserPrincipal p, Model model) {
principal(model, p);
List<CohortRow> rows = new ArrayList<>();
for (Course c : catalog.allCourses()) {
for (Cohort cohort : enrollment.cohortsForCourse(c.id())) {
List<String> students = new ArrayList<>();
for (Enrollment e : enrollment.rosterForCohort(cohort.id())) {
identity.findUser(e.learnerId()).ifPresent(u -> students.add(u.name()));
}
rows.add(new CohortRow(c.title(), cohort.capacity(), cohort.enrolledCount(), students));
}
}
model.addAttribute("cohorts", rows);
return "instructor/cohorts";
}The war story: the association that would have broken everything
The first instinct — and I’ve watched more than one team take it — is to make Enrollment hold a JPA @ManyToOne AppUser learner. Then the template just writes enrollment.learner.name and you delete the whole findUser loop. It compiles. It even works in a demo. And it quietly destroys two of the properties this system is built on.
The first casualty is the module boundary. A direct association means the Enrollment entity imports the Identity entity, and now the two contexts are welded together at the class level. The whole premise of the modular monolith — that you can reason about, test, and one day extract a context on its own — depends on contexts referring to each other only by id. One @ManyToOne and Enrollment can no longer be understood without Identity loaded in the same persistence unit.
The second casualty is subtler and worse: tenant isolation. Enrollment is filtered by @TenantId; AppUser is deliberately global. If you map an association from a tenant-scoped entity to a global one and let Hibernate traverse it, you’ve created a path where a lazy load crosses the isolation boundary without going through the explicit, auditable findUser call. The boundary stops being a single, greppable seam and becomes an emergent property of your fetch graph — which is to say, it stops being a boundary at all.
Referring by id keeps both properties intact. The cost is the explicit loop you see above: the controller asks Enrollment for the roster, then asks Identity, by id, for each name. It is more code than a lazy association. That extra code is the boundary, made visible and testable. When this system grows and Identity moves behind a network call, this loop becomes a batch lookup or a cached view and nothing else in the codebase changes — because nothing else ever reached across the line.
(In production you’d replace the per-learner findUser with a single findAllById(learnerIds) to avoid an N+1 query pattern — the join is the same shape, just batched. The point stands either way: the controller owns the join, the entities don’t.)
The server-rendered views
The UI is Thymeleaf, rendered on the server, no client framework. Each page reuses a shared shell fragment for the role-aware sidebar, so the instructor sees the same navigation everywhere and the active item highlights itself:
<div th:replace="~{fragments/shell :: sidebar('instructor','courses')}"></div>That one line pulls in the entire sidebar — brand, organisation name, role chip, navigation, signed-in footer, and sign-out form — parameterised by two arguments: the role and the active item. The fragment itself branches on the role to render the right menu, and highlights the current page:
<nav class="nav" th:if="${role == 'instructor'}">
<a th:href="@{/instructor}" th:classappend="${active=='dashboard'}?'active'">Dashboard</a>
<a th:href="@{/instructor/courses}" th:classappend="${active=='courses'}?'active'">My Courses</a>
<a th:href="@{/instructor/cohorts}" th:classappend="${active=='cohorts'}?'active'">Cohorts & Roster</a>
<a th:href="@{/instructor/grading}" th:classappend="${active=='grading'}?'active'">Grading</a>
</nav>One fragment serves all three roles — admin, instructor, student — and each page passes its own (role, active) pair. There’s no client-side router, no duplicated header markup, and no risk of an instructor’s page accidentally showing a student’s menu, because the role is supplied by the server from the authenticated principal, not chosen in the browser. It’s the simplest thing that could possibly work, and for a multi-role admin UI it’s also one of the most robust.
The course-detail template is the heart of the workspace: it lists the lessons in order, offers an add-lesson form, and shows a publish button that flips to a “Published” badge once the course is live. Because every action is a plain HTML form posting to a controller route, the entire authoring flow works with JavaScript disabled — a property that matters more for an LMS than for most apps, because institutional and assistive-technology users are a first-class audience (the accessibility argument from Part 9).
<form method="post" th:action="@{'/instructor/courses/' + ${course.id} + '/lessons'}">
<input name="title" placeholder="Topics & partitions" required/>
<textarea name="body" rows="4"></textarea>
<button type="submit">Add lesson</button>
</form>
<form method="post" th:action="@{'/instructor/courses/' + ${course.id} + '/publish'}"
th:if="${!course.published}">
<button type="submit">Publish course</button>
</form>
<span th:if="${course.published}" class="tag">✓ Published</span>Code → file map
Everything in Part 12, and where it lives in the companion repository:
| Concern | File |
|---|---|
| The lesson entity (tenant-scoped, by-id course ref) | catalog/domain/Lesson.java |
| Lesson queries (by course, ordered; count) | catalog/internal/LessonRepository.java |
| Authoring + publish service methods | catalog/CatalogService.java |
| Cohorts-for-course, roster-for-cohort | enrollment/EnrollmentService.java |
| Look up a learner’s name by id (global) | identity/IdentityService.java |
| The instructor UI routes | web/ui/InstructorController.java |
| Templates: list, detail, roster | templates/instructor/{courses,course,cohorts}.html |
| The lessons table + RLS | db/migration/V8__lessons.sql |
Run it yourself
The whole platform comes up with one command. Log in as the seeded instructor and you land in the workspace this article built:
git clone https://github.com/muasif80/tutorial-lms-platform.git
cd tutorial-lms-platform
git checkout part-12
docker compose up -d --build # Postgres + the app, schema auto-migrated
open http://localhost:8080/login # sign in as [email protected] / scholrThe seeded Acme University tenant already has courses and enrolled students, so the roster page has something to show on first boot. A few things worth trying once you’re in:
- Author end to end. Open My Courses → create a course (it starts as a draft) → open it → add two or three lessons and watch them number themselves → hit Publish and see the badge flip. Refresh the page afterwards: because every action is Post/Redirect/Get, nothing is re-submitted.
- See the roster join. Open Cohorts & Roster: each cohort lists its enrolled students by name and shows seats used against capacity. Those names come from the global Identity context, fetched by id — the cross-context join made visible.
- Test the boundary. Sign out and sign back in as
[email protected]/scholr, then manually visit/instructor/courses. You’ll get a403— RBAC refusing the wrong role, not a soft redirect.
Create a new course, add a couple of lessons, publish it, and it becomes available to the student catalogue — which is exactly where Part 13 picks up.
How we know it works
Every part of this series is gated by the same rule: it isn’t done until mvn verify is green in CI. Part 12 adds no shortcuts. The persistence tests run on in-memory H2 in PostgreSQL mode; the new lessons table migrates and the catalog service’s authoring methods exercise the same tenant-scoped path the UI uses. The architecture tests (ArchUnit, from Part 1) still enforce that no context reaches into another’s internals — which is precisely the rule the roster war story is about, now checked by a build that fails if anyone ever adds that tempting @ManyToOne.
That ArchUnit check is the quiet hero of this part. It’s a unit test that reads the bytecode of the whole application and asserts structural rules — for example, that classes in the catalog package don’t depend on the internals of enrollment or identity. When the war story’s temptation arises (just add a @ManyToOne AppUser to Enrollment and be done), the cost isn’t a code-review argument someone has to win; it’s a red build. The boundary is enforced by a machine that never gets tired, never ships under deadline pressure, and never makes an exception “just this once.” Architecture you can’t accidentally violate is the only kind that survives a year of feature work.
Beyond the automated suite, the workspace is verified the way a user would: the platform is deployed live, an instructor signs in, creates a course, adds two lessons, publishes it, and watches the status flip to Published — then opens the roster and sees real enrolled students by name. Every screenshot in this article is of that running system, on the seeded Acme University tenant, not a mock-up.
What Part 12 unlocks
The instructor workspace isn’t just a feature in isolation — it produces the input the rest of the platform consumes. A published course with ordered lessons is exactly what the student needs to discover, enrol in, and work through, which is the whole subject of Part 13: the catalogue lists published courses, enrolment takes a seat in a cohort (the idempotent, seat-capped operation from Part 2), and the course player walks the learner through the lessons authored here, lesson by lesson, recording progress. The roster you built in this part is the same join, viewed from the other side: the instructor sees who’s enrolled; the student sees what they’re enrolled in.
It also sets up Part 14’s admin console, where the organisation-wide view — how many courses are published, which cohorts are filling up, what’s being billed — aggregates exactly the data the instructor and student workspaces generate. Each role’s tools feed the others, which is what turns a set of screens into a platform.
Key takeaways
- The tenant is never in the URL. Inherited from Part 11, the
TenantPrincipalFilterpins the tenant from the session, so the instructor controller carries no tenant id and isolation is automatic. - The server owns ordering and state. Lesson position is computed server-side; publishing is a guarded aggregate transition, not a client-set flag. The client expresses intent; the server decides.
- Post/Redirect/Get on every mutation stops a refresh from duplicating content — essential for an authoring tool.
- Reference across contexts by id. The roster joins tenant-scoped Enrollment to global Identity with an explicit, by-id lookup. The association you didn’t add is what keeps the module boundary and tenant isolation intact.
- Server-rendered, framework-free UI keeps the whole flow working without JavaScript — an accessibility win that matters for an LMS.
Frequently asked questions
Why server-rendered Thymeleaf instead of a React or Next.js front end?
For this series the goal is one deployable that demonstrates the architecture, not a separate front-end stack to operate. Thymeleaf renders on the same Spring Boot server, shares the security context directly, and keeps the whole authoring flow working without JavaScript — an accessibility and simplicity win. A production team might layer a SPA on top via the existing REST API, but the server-rendered version is the honest, runnable baseline.
How does an instructor only see their own organisation’s courses?
The tenant is resolved from the authenticated session by TenantPrincipalFilter before any controller runs, and Hibernate’s @TenantId plus PostgreSQL Row-Level Security filter every query by it. The instructor controller never receives or passes a tenant id, so there is no request the instructor can craft that reaches another tenant’s data.
Why compute lesson position on the server instead of letting the client send it?
Because the server owns ordering. If clients set their own positions you can get duplicates or gaps, and two concurrent adds could collide. Computing count + 1 on each insert keeps the sequence consistent regardless of what the form posts — the same “server owns state, client expresses intent” discipline used for enrolment and assessments earlier in the series.
Why is publishing a method on the aggregate rather than a boolean setter?
So the rule for whether a course may be published lives in exactly one place. Today it’s a simple, idempotent draft→published transition; when a rule like “a course needs at least one lesson to go live” arrives, it goes inside Course.publish() and every caller is protected automatically. A public boolean setter would scatter that decision across every controller that flips it.
Why not add a JPA association from Enrollment to the learner’s user record?
Because it would weld two bounded contexts together and create a fetch path that crosses the tenant-isolation boundary implicitly. Enrollment is tenant-scoped; the user record is global. Referencing the learner by id and looking the name up explicitly keeps the module boundary hard and the isolation boundary auditable — the explicit lookup is the seam, which is what lets a context be extracted later without rewriting its callers.
Can I use this as the starting point for a real LMS?
It’s an educational reference architecture, MIT-licensed, designed to teach production patterns — multi-tenancy, idempotency, guarded state machines, module boundaries — on a runnable codebase. It’s a strong skeleton to learn from and adapt, but you’d harden it (richer content types, audit logging, rate limiting, a managed database) before trusting real learners and real money to it.
