

Every part of this series so far has built something a learner touches directly — the domain, the multi-tenant data, video, and assessments and live classes. Part 5 builds the thing nobody sees and everything depends on: the event backbone. Progress tracking, analytics, recommendations, certificates, notifications, the at-risk-learner email an instructor relies on — all of it is downstream of events. Which means a single, brutal truth governs this entire layer: if your events are unreliable, every feature built on them is quietly, confidently wrong. This is the part where we make the events reliable, and the pattern at its center — the transactional outbox — is the most important idea in the article.
Scholr learned this the way most teams do: from a support ticket that should have been impossible. A learner finished the final lesson of a certification course, saw the green checkmark, closed their laptop — and three days later got an automated email telling them they were 90% complete and at risk of falling behind. The course-completion record in the primary database was correct. The analytics warehouse, which drove the email, said otherwise. Nobody had a bug in the obvious place; the grading worked, the warehouse query worked. The data had simply diverged somewhere between the database and the stream, and once it diverged, nothing downstream could tell. That divergence has a name, and a fix.
The learning-events model: what an event is, and what it must contain
Before reliability, taxonomy. An event is an immutable statement that something happened, in the past tense: enrollment.created, lesson.completed, quiz.submitted, certificate.issued. Not a command (“complete this lesson”) and not a row you mutate — a fact you append. Scholr’s events share a small, deliberate shape: a unique id, a tenant id, a type, the id of the aggregate they concern (which doubles as the ordering key), an immutable timestamp, and a self-contained payload.
That last property is the one teams skimp on and regret. A consumer must be able to act on an event without calling back into the producing service — both because the callback couples the two systems, and because by the time the consumer runs, the source row may have changed. So the payload carries the ids it needs (here, a tiny learnerId:courseId snapshot), and the references-across-aggregates-by-id discipline from Part 2 now extends across the entire stream.

There are standards for this — xAPI (the “Tin Can” statement format of actor-verb-object) and Caliper from IMS Global — and they matter when you need to interoperate with other learning systems or an external LRS (the subject of Part 8). Adopt them at the edges, where you export to or import from someone else’s system. Internally, a lean event schema you control evolves faster; you can always project your internal events into xAPI statements at the boundary. Standardize where you must interoperate, stay lean where you don’t.
| Event schema | Strength | Cost | Use it |
|---|---|---|---|
| Lean internal events (our choice) | Fast to evolve; tiny payloads | Not portable as-is | Everywhere inside the platform |
| xAPI (actor-verb-object) | Portable to any LRS | Verbose; statement ceremony | At the edge, exporting to an LRS (Part 8) |
| Caliper (IMS) | Rich academic metric model | Heavier to adopt | Edu-standards interop |
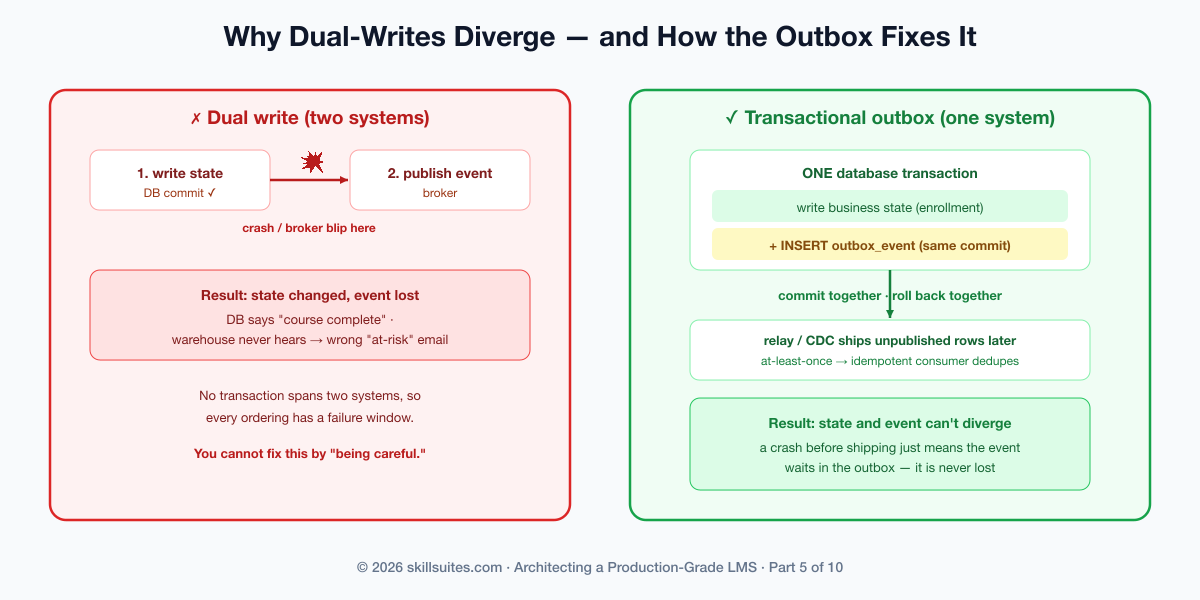
Why dual-writes corrupt data: the bug behind the wrong email
Here is exactly what went wrong at Scholr, in sequence. The naive way to emit an event is the obvious way: do the database work, commit it, then publish to the broker.
// THE DUAL-WRITE ANTI-PATTERN — do not do this
@Transactional
void completeLesson(...) {
progressRepo.save(...); // 1) write business state, commit
}
// 2) ...then publish, in a separate step
broker.publish("lesson.completed", event);Two writes to two different systems (the database and the broker) with no shared transaction. Now enumerate the ways it breaks, because each one happened to someone:
- The commit succeeds, then the process crashes (or the broker is briefly down) before the publish. State changed, no event. The warehouse never learns the lesson was completed — Scholr’s exact bug.
- The publish succeeds, then the transaction rolls back. Event with no state. Downstream now believes something that never happened.
- Both succeed but in the wrong order under concurrency, and a consumer sees
lesson.completedbeforeenrollment.created.
You cannot fix this by being careful, retrying the publish, or reordering the two writes — every ordering has a failure window, because there is no atomicity spanning two systems. The only fix is to make the event part of one transaction with the state change. Which is precisely what the outbox does.
| Failure point | Naive dual-write result | Transactional outbox result |
|---|---|---|
| Crash after commit, before publish | State saved, event lost | Event is in the same commit; relay ships it later |
| Publish succeeds, tx rolls back | Phantom event, no state | Event rolled back with the state — never existed |
| Broker down at write time | Write fails or event lost | Write succeeds; event waits in the outbox |
| Duplicate publish on retry | Double-processed downstream | Idempotent consumer dedupes it |
The transactional outbox: one transaction, no divergence
The outbox pattern is deceptively simple: instead of publishing to the broker, the business transaction writes the event to an outbox table in the same database, on the same connection, inside the same transaction as the state change. The two commit together or roll back together. There is no window in which one happened and the other didn’t, because to the database they are one write.
In Scholr’s code the writer deliberately has no transaction of its own — it joins whatever transaction the calling service already opened:
@Component
public class OutboxWriter {
// no @Transactional here — joins the caller's transaction on purpose
public OutboxEvent append(String type, UUID aggregateId, String payload) {
return outbox.save(OutboxEvent.of(type, aggregateId, payload, Instant.now(clock)));
}
}So enrollment, which was already atomic from Part 2, now emits its event inside that same atomic block — the enrollment row, the seat-count bump, and the enrollment.created event all commit as one unit:
@Transactional
public Enrollment enroll(UUID cohortId, UUID learnerId) {
return enrollments.findByCohortIdAndLearnerId(cohortId, learnerId)
.orElseGet(() -> {
Cohort cohort = cohorts.findById(cohortId).orElseThrow(...);
Enrollment saved = enrollments.save(cohort.enroll(learnerId));
cohorts.save(cohort);
outbox.append("enrollment.created", saved.id(), learnerId + ":" + cohort.courseId());
return saved; // event + state commit together, or not at all
});
}Notice the event is written only on the new-enrollment branch, not on the idempotent retry — so a duplicated request never produces a duplicate event at the source. Shipping those events to the broker is a separate job. A relay (a polling publisher, or change-data-capture like Debezium tailing the table’s write-ahead log) reads unpublished rows and pushes them out:
@Transactional
public int relayPending() {
List<OutboxEvent> pending = outbox.findByPublishedFalseOrderByOccurredAtAsc();
for (OutboxEvent e : pending) {
publisher.publish(e); // at-least-once: ship first...
e.markPublished(); // ...then mark; a crash between re-ships, never loses
}
return pending.size();
}This is intentionally at-least-once: it ships, then marks published, and a crash in between simply re-ships on the next pass. We never lose an event; we accept the occasional duplicate and make the consumer absorb it. That single decision — lose nothing, tolerate duplicates, dedupe downstream — is the spine of the whole pipeline, and the next section is why.
The relay here is a simple poller because it makes the pattern legible, but in production you have a choice for how unpublished rows reach the broker, and it’s worth making deliberately.
| Relay mechanism | How it ships events | Trade-off |
|---|---|---|
| Polling publisher (shown here) | Query unpublished rows on an interval | Dead simple; adds a little latency and DB load |
| Change-data-capture (Debezium) | Tail the table’s write-ahead log | Low latency, no polling; a CDC pipeline to run |
| Listen/notify | DB notifies the relay on insert | Near-real-time; tied to one database’s feature |
All three preserve the one property that matters — the event was committed atomically with the state, so however it ships, it cannot have been lost. The choice is purely latency-versus-operational-cost; the correctness was already won at the outbox write.
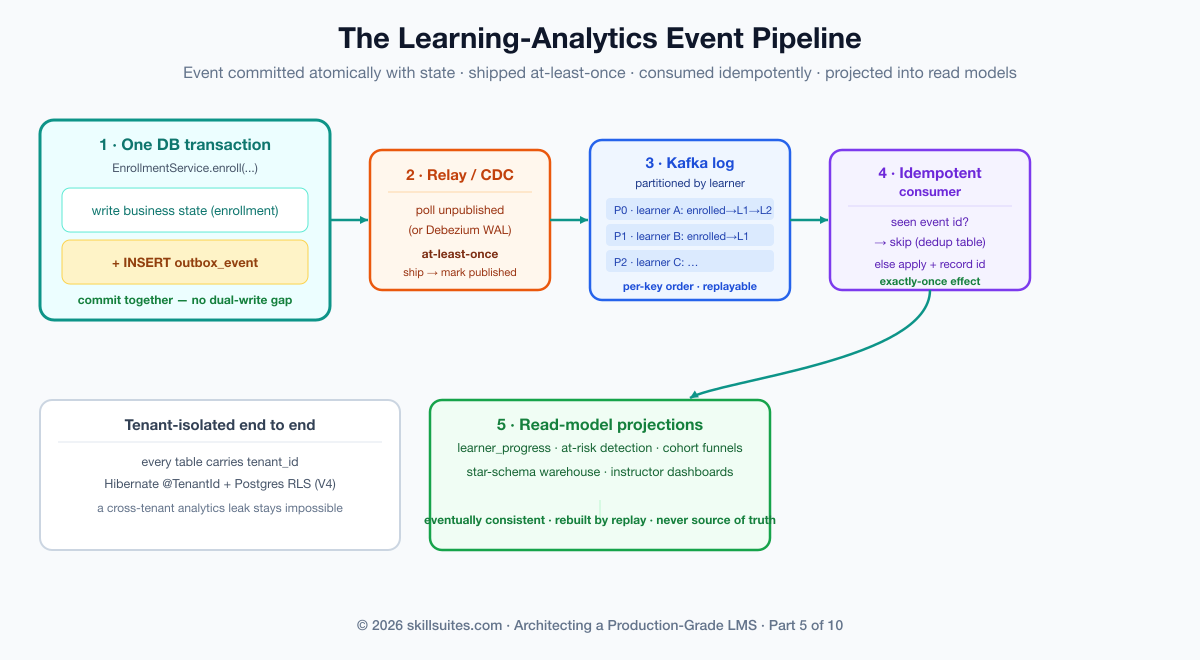
The streaming backbone: partitions, ordering, and schemas
Once events leave the outbox they land on a log — Kafka or Redpanda — and three of its properties decide what your analytics can and cannot do.
Partitioning is the first and most consequential. A topic is split into partitions, and the log guarantees ordering only within a partition, never across them. So the partition key is an architectural decision, not a config detail: Scholr keys by aggregate id (effectively by learner), which guarantees that all of one learner’s events — enrolled, then lesson one, then lesson two — arrive at the consumer in order, while different learners’ events parallelize across partitions for throughput. Key by the wrong thing and you either lose the ordering you need or funnel everything through one partition and lose all parallelism. The rule: partition by the entity whose event order matters.
Retention is the second. A log is not a queue that empties; it keeps events for a configured window (or forever, compacted). That is what makes a projection rebuildable — delete the read model, replay the log, and it reconstructs itself. Schema evolution is the third: a schema registry with Avro or Protobuf lets producers and consumers evolve independently, provided changes stay backward-compatible (add optional fields, never repurpose one). Events are immutable and long-lived; a schema you can’t evolve safely becomes a cage.
| Log property | What it gives you | The decision it forces |
|---|---|---|
| Partitioning | Per-key ordering + parallelism | Key by the entity whose order matters (learner/tenant) |
| Retention | Replayable, rebuildable projections | How long must you be able to replay? |
| Schema registry | Independent producer/consumer evolution | Backward-compatible changes only |
Delivery semantics: at-least-once plus idempotent consumers
Here is the decision teams agonize over and usually get backwards. The instinct is to chase exactly-once delivery — guarantee the broker hands each event to the consumer one time, ever. It is achievable in narrow conditions and operationally brutal everywhere else, and it is almost always the wrong thing to spend your reliability budget on. The pragmatic, robust design is at-least-once delivery with exactly-once effects: let the broker redeliver freely, and make the consumer’s action idempotent so a duplicate changes nothing.
Scholr’s consumer does this with a dedup table. Before acting on an event, it checks whether that event’s id is already recorded; if so, it skips. The check and the action and the record all commit in one transaction, so a crash mid-apply redelivers and re-applies cleanly:
@Transactional
public boolean apply(OutboxEvent event) {
if (processed.existsById(event.id())) {
return false; // already handled — at-least-once delivery, exactly-once effect
}
switch (event.type()) {
case "enrollment.created" -> { var p = upsert(event); p.markEnrolled(); progress.save(p); }
case "lesson.completed" -> { var p = upsert(event); p.incrementLessonsCompleted(); progress.save(p); }
default -> { /* not interesting to this projection, but still mark it processed */ }
}
processed.save(new ProcessedEvent(event.id(), Instant.now(clock)));
return true;
}This is the same idempotent-write discipline that made enrollment safe in Part 2 and exam submission safe in Part 4 — a unique key turning “did I already do this?” into a cheap lookup. The dividend is enormous: the relay can re-ship, the broker can redeliver, a consumer can crash and restart, and the learner’s progress count is still exactly right.
| At-least-once | Exactly-once delivery | At-most-once | |
|---|---|---|---|
| Lost events? | Never | Never | Possible |
| Duplicates? | Possible (consumer dedupes) | None | None |
| Operational cost | Low | High / fragile | Low |
| Verdict for an LMS | Our choice + idempotent consumers | Rarely worth it | Unsafe — data loss |
Computing progress correctly: out-of-order, late, and replayed events
A reliable stream is necessary but not sufficient; the consumer still has to do correct math on it. Three realities make that harder than summing a column. Events can arrive out of order across partitions (which is why Scholr keys by learner, so a single learner’s events stay ordered). Events can arrive late — a mobile client that was offline flushes yesterday’s lesson completions today — so progress logic must be commutative where it can be (a count of completed lessons doesn’t care about arrival order) and timestamp-aware where it can’t. And the whole stream can be replayed to rebuild a projection, which only produces the same answer if every step is idempotent.
That is why Scholr’s LearnerProgress is a projection, never a source of truth. It is eventually consistent with the enrollment and learning aggregates, it can be deleted and rebuilt from the log at any time, and — because the consumer dedupes — replaying ten thousand events or re-delivering the same one a hundred times yields identical numbers. When a projection’s logic has a bug, you don’t migrate data; you fix the consumer and replay. That operational superpower is only available because the events are reliable and the consumer is idempotent.
There is a deeper design principle hiding in that incrementLessonsCompleted() call, and it is worth making explicit because it decides which progress metrics are safe to compute on a stream. An operation that is commutative and idempotent — “this lesson is completed” applied to a set of completed lessons — is order-independent and replay-safe by construction: it does not matter whether lesson three’s event arrives before lesson one’s, and applying it twice is the same as applying it once (because a set already containing the lesson is unchanged). Scholr’s progress is modeled exactly this way, as a count derived from a set of completed-lesson facts, rather than as a running counter you blindly +1 on every message. The naive counter is the trap: replay it, or let one event redeliver, and it over-counts. The set-based formulation cannot. Whenever you can express a metric as a fold over a set of idempotent facts rather than a sequence of mutations, do — it is the difference between a projection you can trust and one you have to babysit.
Some computations genuinely cannot be made order-independent — a “current streak of consecutive active days,” or anything that depends on the gap between events. For those, the stream processor must be timestamp-aware: it buffers within a bounded watermark window so that a late event (the offline mobile client flushing yesterday’s completions) is slotted into the correct day rather than treated as today’s, and it only finalizes a window once the watermark has passed. This is the heart of stateful stream processing — the consumer holds a little state per key and reasons about event time, not arrival time. Scholr keeps the count-style metrics (the bulk of progress) in the simple idempotent projection, and isolates the genuinely time-ordered metrics into their own windowed processor, so the easy ninety percent stays trivially correct and only the hard ten percent pays for windowing.
Even with all of that, distributed pipelines drift — a consumer bug ships, an event is mis-handled for an hour before anyone notices, a downstream system was briefly misconfigured. The backstop is a periodic reconciliation job: a batch process that recomputes the projection from the system of record (or from a full replay of the log) and compares it against the live projection, repairing or alerting on any divergence. Reconciliation is not an admission that the streaming layer is wrong; it is the seatbelt that lets you move fast on the streaming layer, because you know a slow, authoritative process will catch and heal anything that slips through. The combination — fast eventually-consistent projections in the hot path, a slow exact reconciliation in the background — is how you get both responsiveness and correctness without choosing.
From stream to insight: the analytics pipeline
With trustworthy events flowing, the analytics pipeline is almost anticlimactic — which is the point. Events stream into a warehouse organized as a star schema: a central fact table of events (one row per learning event, narrow and append-only) surrounded by dimension tables for learners, courses, cohorts, and time. The shape is deliberate — facts are immutable and enormous, dimensions are small and descriptive, and joining one fact table to a handful of dimensions is exactly what a columnar warehouse is optimized for. From there the questions an LMS exists to answer become ordinary queries: course-completion funnels (how many enrolled → started → reached the midpoint → finished), cohort comparisons, and time-to-completion distributions.
The query instructors care about most is at-risk-learner detection, and it is worth making concrete because it shows why the reliable stream underneath matters so much. “At risk” is a definition, not a fact — typically something like enrolled, less than X% complete, and no lesson.completed event in the last N days, weighted by how far behind the cohort’s median pace they are. Every term in that definition is a fold over the event history: percent-complete is a count of completion facts over the course’s lesson count; “days since last activity” is the gap between now and the latest event’s timestamp; “behind the cohort median” compares this learner’s pace projection to the cohort’s. Because all of it is derived from the log, when the pedagogy team inevitably refines the definition — add quiz attempts as an activity signal, change the window from 7 days to 5 — you change the query and replay, and you instantly have correct at-risk flags for the entire history. Contrast the alternative: had “at risk” been computed and stored imperatively at event time, changing the definition would mean the past is simply wrong and unrecoverable. The crucial discipline is that these are all derived, recomputable views over the event log; the log is the asset, the metrics are opinions about it.
This separation — a transactional system of record on one side, a recomputable analytical projection on the other, joined only by a reliable event stream — is the same boundary the production engineering playbook draws between the thing that must be correct now and the thing that can be eventually consistent. Get the stream right and both sides get simpler.
Compliance across the pipeline: GDPR when data has fanned out
An event backbone creates a compliance problem worth naming, because it is easy to miss until a deletion request arrives. Once a learner’s events have fanned out across topics, consumers, projections, and a warehouse, “delete my data” (the GDPR right to erasure) is no longer one DELETE — the data is in many places, and an append-only log is, by design, not something you go edit. Two patterns make this tractable. Crypto-shredding: encrypt personal fields with a per-learner key and, on an erasure request, destroy the key — the events remain in the immutable log but become unreadable, satisfying erasure without rewriting history. And keying projections by a pseudonymous id so most analytics never touch personal data at all, with the identity mapping held in one place you can delete. Designing for erasure up front is far cheaper than retrofitting it across a dozen consumers later.
The war story, resolved — and what we’d do differently
Scholr’s wrong-email incident was a textbook dual-write divergence: a completion committed to the database, the follow-up publish lost to a momentary broker blip, and a warehouse that never heard the news driving an automated email off stale data. The fix was the outbox — the completion event now commits in the same transaction as the completion itself, so it cannot be lost — plus idempotent consumers so the relay can re-ship safely, plus partitioning by learner so a single learner’s events stay ordered. After it shipped, the warehouse and the system of record could no longer disagree, because there was exactly one source of both the state and the event.
That fix exposed a second incident, and it is the one that validated the whole “idempotent consumer” insistence. A few weeks later the team deployed a bug in the progress consumer and, to repair the bad data, did the now-blessed thing: reset the consumer’s offset and replayed the log from the beginning. The replay re-delivered months of events in minutes — a reprocessing storm — and a naive consumer would have melted the database under the write load and, worse, double-counted everything it touched. Scholr’s didn’t: the dedup table absorbed every event that had already been applied (skipped as a cheap existence check), the count-as-a-fold projection re-derived identical numbers, and the only real cost was a burst of harmless reads. The storm was a non-event precisely because the day-one decisions — at-least-once delivery, exactly-once effects, commutative metrics — had already paid for it. A team that had chased exactly-once delivery instead would have had neither the freedom to replay nor the safety to survive it.
The episode also surfaced the operational metric you actually watch in production: consumer lag — how far behind the head of the log each consumer is. Healthy lag hovers near zero; a climbing lag means a consumer is falling behind (a slow downstream, a hot partition, a deploy gone wrong) and your projections are getting staler by the second even though nothing has “failed.” Lag is the early-warning system for an event pipeline the way error rate is for a request path, and it is the number Scholr now alerts on long before any learner notices a stale dashboard.
What would we do differently? We would have started with the outbox on day one, rather than reaching for “just publish after the commit” and discovering the gap in production — retrofitting an outbox means auditing every place that ever published an event. We would have made consumers idempotent from the first one, not the first incident, because at-least-once delivery is not an edge case you might hit but the normal behavior of every real broker. And we would have treated every projection as disposable and rebuildable from the start, so that fixing an analytics bug was a replay rather than a data migration. The thread through all of it is the same as the rest of this series: decide the hard reliability property up front, encode it in one place, and prove it.
Get the code and run it
Everything above is in the companion repository, evolving the same codebase the series has built since Part 1. Each part has its own branch frozen at that lesson’s checkpoint, and main always holds the latest cumulative code.
# this part's exact code:
git clone https://github.com/muasif80/tutorial-lms-platform.git
cd tutorial-lms-platform
git checkout part-5
# the latest cumulative build is always on main:
git checkout mainVerify it the way the build does — the atomic outbox write, the at-least-once relay, the idempotent consumer that won’t double-count a redelivered event, the rebuilt progress projection, and tenant isolation across the stream all run under one command:
mvn verify # green = atomic outbox + at-least-once relay + idempotent consumer all holdWhere each idea in this article lives in the code:
- The transactional outbox (atomic event-with-state) —
events/domain/OutboxEvent.java+events/OutboxWriter.java, called insideenrollment/EnrollmentService.enroll. - The at-least-once relay —
events/OutboxRelay.javashipping through theEventPublisherport (Kafka plugs in here; the in-memory default isInMemoryEventPublisher.java). - The idempotent consumer + dedup —
events/ProgressProjection.java+events/domain/ProcessedEvent.java. - The rebuildable read model —
events/domain/LearnerProgress.java. - Tenant isolation + RLS for the pipeline tables —
db/migration/V4__events.sql. - The proof —
EventsPipelineTest.javaasserts atomic write, at-least-once relay, idempotent consumption, and correct progress.
Frequently asked questions
What is the transactional outbox pattern and why do I need it?
It’s a way to publish an event reliably without the dual-write problem. Instead of writing your business change to the database and then separately publishing to a broker — two writes with no shared transaction, so a crash between them leaves the two systems disagreeing forever — you write the event to an “outbox” table in the same database transaction as the state change. They commit or roll back together, so the event can never be lost or phantom. A separate relay (or change-data-capture) then ships unpublished outbox rows to the broker. You need it any time a state change must reliably produce an event, which in an LMS is nearly always.
At-least-once or exactly-once for learning events?
At-least-once delivery plus idempotent consumers. True exactly-once delivery is operationally fragile and rarely worth it; at-least-once never loses an event and lets you tolerate the occasional duplicate by making the consumer idempotent — record each event id before acting on it, and skip ids you’ve already processed. The effect is exactly-once, the machinery is far simpler, and the consumer can crash, restart, or replay the stream without corrupting the result.
How do I compute accurate progress from events?
Treat progress as a projection (a read model) rebuilt from the event stream, never as the source of truth. Make the consumer idempotent so duplicates and replays don’t double-count, partition the stream by learner so one learner’s events stay ordered, and prefer commutative aggregations (like a count of completed lessons) that don’t depend on arrival order. Because the projection is derived, you can fix a bug in the logic and simply replay the log to recompute, rather than migrating data.
How do I honor GDPR deletion across a streaming pipeline?
Don’t try to edit the immutable log. Use crypto-shredding — encrypt each learner’s personal fields with a per-learner key and destroy the key on an erasure request, so the events remain but become unreadable — and key your analytics projections by a pseudonymous id so most of the pipeline never holds personal data, with the identity mapping in one deletable place. Designing for erasure up front is far cheaper than retrofitting it across every consumer.
Conclusion
The event backbone is the part of an LMS nobody asks for and everything needs. We modeled events as immutable, self-contained facts; closed the dual-write gap with a transactional outbox so state and event commit as one; shipped them at-least-once and made consumers idempotent so duplicates and replays are harmless; partitioned by learner so progress math stays correct; and treated every analytic as a rebuildable projection over a reliable stream. Scholr’s wrong-email incident — and the whole class of “the warehouse disagrees with the database” bugs — is now impossible by construction.
The full, tested implementation — the outbox, the relay, the idempotent consumer, and the progress projection, all verified by a build that proves them — is on the part-5 branch of the companion repository. ⭐ Star it to follow the build. Next, in Part 6, we put that event stream to work powering search, recommendations, and AI tutoring — index freshness, hybrid and vector retrieval, and the cold-start problem.
