

Scholr was a success story right up until it wasn’t. The product — a clean, multi-tenant learning platform sold to training companies and universities — had grown from 50 organizations to 500 in eighteen months. Then the cracks appeared all at once: a single customer’s bulk enrollment import would lock the database and slow everyone down; the monthly video bill arrived three times higher than the forecast; the course catalog search started returning courses that had been unpublished days ago; and when a star instructor went live to forty thousand learners, the real-time servers fell over in under a minute. None of these were “bugs” in the ordinary sense. They were the predictable failure modes of an architecture that was designed for a demo and asked to behave like a platform.
This article is the first of a ten-part series that builds a production-grade Learning Management System the way a senior engineer actually would — and it starts where every durable system starts: not with a framework, but with the product, the domain, and the architecture. The uncomfortable truth that the Scholr story illustrates is that most LMS builds don’t fail on technology. They fail on domain modeling and unclear boundaries. Get the product and the domain right and the hard distributed-systems work in the parts that follow becomes tractable. Get them wrong and no amount of Kubernetes, caching, or clever code will save you; you will simply scale your confusion.
So this part has no service mesh and no Kafka. It has something more valuable: the blueprint that makes the next nine parts possible. By the end you’ll have the domain model, the non-functional requirements that actually drive architecture, the decisive monolith-versus-microservices call, and the high-level reference architecture that the rest of the series fills in one layer at a time.
📦 The code: the companion implementation lives at github.com/muasif80/tutorial-lms-platform. Part 1’s scaffold — the modular-monolith structure, the domain model, the seat-invariant
Cohortaggregate, and the ArchUnit boundary tests — is on thepart-1branch. ⭐ Star it to follow along as it grows one part at a time.
Why we start with the domain, not the stack
There is a reflex, under deadline pressure, to open the IDE and start wiring up controllers. It feels productive. It is, in fact, the single most expensive mistake you can make on a system you intend to keep for years. Architecture decisions made before you understand the domain are guesses dressed up as code, and guesses calcify. The data model you ship in month one is the data model you are still apologizing for in year three.

A great system designer inverts the reflex. They start with the problem and its constraints and let the architecture emerge:
- Clarify the real requirement. Not “build an LMS,” but “let an organization deliver, track, and certify learning to its people, in a way that is auditable, accessible, and isolated from every other organization.”
- Surface the constraints. Multi-tenancy. Scale. Availability. Data residency and compliance. Who is allowed to see whose data.
- Decompose the problem into areas with clear responsibilities and clear boundaries.
- Identify the genuinely hard parts — for an LMS, that’s video at scale, real-time, the event backbone, search freshness, and operating it all — and design specifically to tame them.
- Choose technology last, to fit the design. We’ve chosen Spring Boot and PostgreSQL for this series, but notice that the choice comes at the end of the reasoning, not the start.
The rest of this article walks that path for Scholr.
What an LMS actually is in 2026
It is tempting to describe an LMS as “a website with videos and quizzes.” That description is how you end up with the Scholr crisis. A modern LMS is a multi-sided platform serving at least four distinct kinds of user, each with conflicting needs:
- Learners want to find the right course, make progress on any device (including offline, on a train), and prove what they completed.
- Instructors / authors want to build and version rich courses, see how their cohorts are doing, and grade at scale without drowning.
- Organization admins want to manage their people, enforce learning paths, run reports, and trust that their data is theirs alone.
- Platform operators (you) want all of the above to run reliably and affordably across hundreds of tenants without a 2 a.m. page every week.
What makes this genuinely hard is that these needs conflict. The instructor wants rich, flexible authoring; the platform operator wants a constrained content model that’s cheap to store and fast to render. The org-admin wants deep custom reporting; the architect wants a schema that doesn’t buckle under it. The learner wants instant, always-available video; the CFO wants the egress bill to stop growing. An LMS is, at bottom, a negotiation between four parties who never meet, and the architecture is where that negotiation is settled. Design for only one of them — usually the demo’s happy-path learner — and the other three break you in production, exactly as they broke Scholr.
That last constraint — multi-tenancy — is the defining property. A B2C course site serves one logical audience. A B2B LMS like Scholr serves hundreds of organizations whose data, branding, roles, and policies must be isolated from one another while sharing the same code and, often, the same database. Almost every hard decision in this series traces back to that one word.
Build, buy, or platform?
Before writing a line, the honest founder asks whether to build at all. The answer depends on where your differentiation lives.
| Option | When it’s right | The cost |
|---|---|---|
| Buy (Moodle, Canvas, a SaaS LMS) | Learning delivery is a supporting capability, not your product | Limited differentiation; you live inside someone else’s model |
| Platform (build on an LMS API / headless) | You need custom UX but standard learning plumbing | Vendor lock-in; you inherit their scaling ceilings |
| Build | The learning experience is your product and your edge | Everything in this series — but you own the model and the IP |
We’re building, because the entire point of the series is to own the domain model and the architecture — the assets that actually appreciate. (That’s also the strategic lesson behind turning any build into reference material: the engine and the model are the durable value, long after a particular UI is forgotten.)
Modeling the domain: bounded contexts
Here is where most LMS projects quietly go wrong. They model “the database” — one big schema where a users table is referenced by everything, a courses table grows forty columns, and every feature reaches into every table. It works in the demo. At 500 tenants it’s a tar pit: every change risks every feature, and no one can reason about the whole.
The discipline that prevents this is Domain-Driven Design, and its central tool is the bounded context — a self-contained area of the domain with its own model, its own language, and a clear boundary across which it talks to other contexts through explicit contracts rather than shared tables. For an LMS, the contexts fall out naturally once you stop thinking in tables and start thinking in responsibilities:
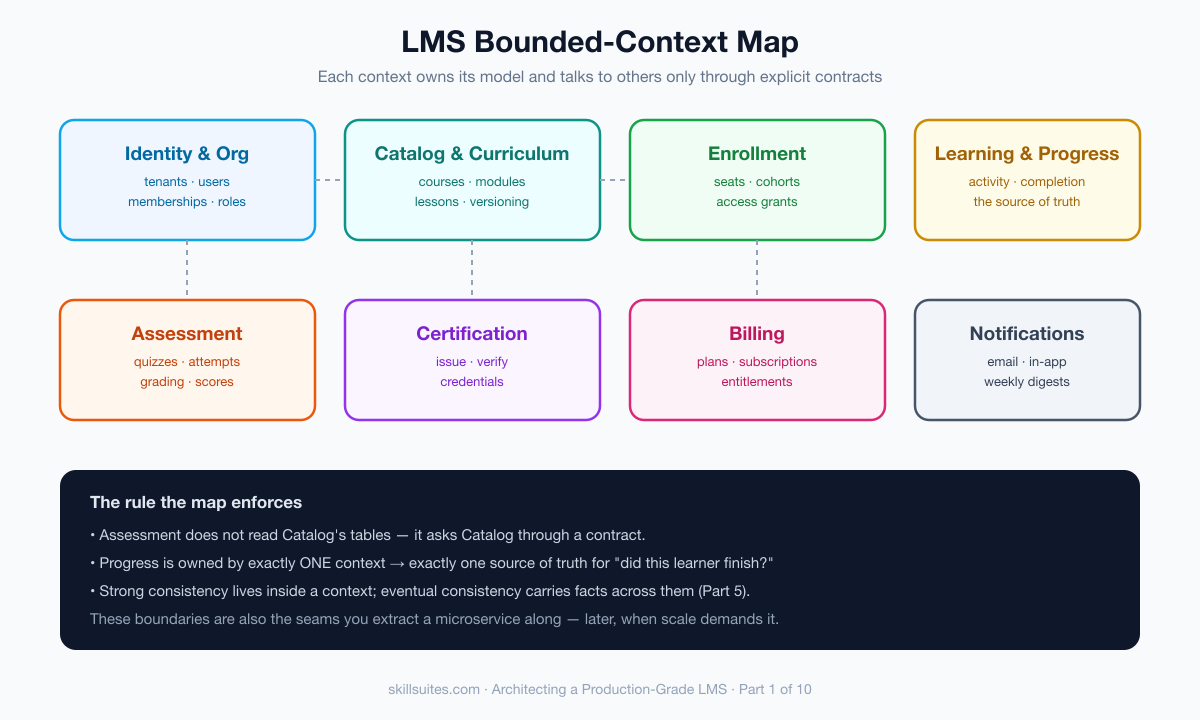
- Identity & Organization — tenants, users, memberships, roles. The context that answers “who is this, which org, and what may they do?”
- Catalog & Curriculum — courses, modules, lessons, and how they’re structured and versioned. The authoring side of the world.
- Enrollment — who is enrolled in what, seats, cohorts, and access grants. The bridge between people and content.
- Learning & Progress — what a learner has actually done; the running record of progress and completion.
- Assessment — quizzes, attempts, grading, and scores. Correctness-critical and, as we’ll see in Part 4, surprisingly subtle.
- Certification — issuing and verifying credentials once the rules are met.
- Billing — plans, subscriptions, and entitlements (Part 7 in full).
- Notifications — email, in-app, and the weekly digests that keep learners coming back.
The power of this map is what it forbids. The Assessment context does not reach into the Catalog’s tables; it asks the Catalog, through a contract, for the questions it needs. Progress is owned by exactly one context, so there is exactly one source of truth for “did this learner finish?” — a fact that will matter enormously when we build the event pipeline in Part 5 and discover how easily progress data gets corrupted by careless writes.
The contexts aren’t islands; they relate, and naming those relationships is part of the design — the discipline of context mapping. Some are customer–supplier, where a downstream context depends on an upstream one (Enrollment depends on Catalog’s published courses). Some need an anti-corruption layer — a translation seam that keeps a messy external model (a payment provider, a third-party SCORM package) from leaking its concepts into a clean domain. A very few legitimately share a small shared kernel, like the TenantId value object every context must honor. What you avoid at all costs is the implicit relationship: the foreign key one team quietly adds into another context’s table “just for now,” which silently fuses two contexts into one and undoes the entire design. Boundaries are only boundaries if something defends them.
The ubiquitous language
Bounded contexts come with a second discipline that sounds trivial and saves years: name things precisely, and use those names everywhere — in conversations, in code, in the database. An LMS is a minefield of near-synonyms. Is a “course” the abstract syllabus or a specific run of it? Is a “class” a synonym for course, or a scheduled live session? What’s a “cohort” versus a “section” versus an “offering”? Teams that never settle this spend a year discovering that the word “course” means three different things in three parts of the codebase, and refactoring the confusion out at ten times the cost.
For Scholr we fix the language early: a Course is the versioned definition of learning content; an Offering is a scheduled run of a course for a cohort; a Cohort is a group of learners progressing together; a Session is a single live class within an offering. These aren’t the only valid choices — but choosing some consistent set, and enforcing it, is non-negotiable.
The cost of getting the domain wrong
It’s fair to ask whether this rigor earns its keep, or whether it’s architecture astronomy. The answer is in the refactor tax. A data model is the single most expensive thing in a system to change once real data is in it: every change demands a migration, a backfill, a backward-compatibility window, and a measure of luck. And a feature built on a confused model isn’t a bug you fix in an afternoon — it’s a fault line that every future feature is then built on top of, so the cost of the original mistake doesn’t stay fixed; it compounds with every release. Scholr’s progress-tracking corruption was never one bad function. It was years of features quietly trusting a “did this learner finish?” answer that two different writers disagreed about, and unwinding it meant touching everything that had come to depend on the wrong shape. The domain work in this article is cheap precisely because it happens before any of that concrete sets. An afternoon of context mapping routinely saves a quarter of refactoring later — a trade a senior engineer makes without hesitation, and the reason we spend Part 1 here instead of in the IDE.
Identity, tenancy and access: the spine that touches everything
One context deserves special attention in Part 1 because it threads through every other: Identity & Organization. In a multi-tenant LMS, almost nothing is global. A user belongs to an organization; a course belongs to an organization; a query that forgets to scope by organization is, at best, a bug and, at worst, a data breach that ends a contract. So the very first concept the whole system shares is the tenant, usually carried as a TenantId value object that rides along with every request and constrains every query.
On top of the tenant sits a model of people and what they may do. The same human might be a learner in one organization and an instructor in another, so identity is global but membership and roles are per-organization. Roles (learner, instructor, org-admin) grant coarse capabilities; finer rules — “an instructor may grade only their own cohorts” — need attribute-based checks that weigh the relationship between the actor and the resource. Getting this model right is what lets the platform safely serve hundreds of organizations from one codebase; getting it wrong is the fastest way to leak one tenant’s data into another.
We build the tenancy strategy and the authorization model properly in Part 2 — it’s a one-way-door decision and deserves its own treatment. What matters in Part 1 is recognizing that Identity & Org is not just another box on the map; it’s the spine. Every other context assumes a tenant and an authenticated, authorized actor, and the integrity of the whole platform rests on that assumption being unbreakable.
The non-functional requirements that actually drive architecture
Junior engineers list features. Senior engineers obsess over non-functional requirements, because the features are easy and the NFRs are where systems live or die. For an LMS handling other organizations’ people and money, the NFRs aren’t decoration — they dictate the architecture. Here are the ones that shape every decision in this series, and the design response each demands.
| NFR | Why it matters for an LMS | Design response (and where the series delivers it) |
|---|---|---|
| Tenant isolation | One org’s data leaking to another is an existential, contract-ending failure | A deliberate tenancy model with isolation enforced structurally (Part 2) |
| Scale & elasticity | Traffic is spiky — enrollment waves, exam deadlines, a viral course | Stateless services, async work, autoscaling (Parts 4, 10) |
| Availability & SLOs | An LMS down during a certification deadline is a crisis | Resilience patterns, multi-region, error budgets (Part 10) |
| Auditability | Compliance and disputes require a defensible record of who did what | An immutable event log and audit trail (Parts 5, 10) |
| Data residency & privacy | FERPA, GDPR, and institutional rules govern learner data | Residency-aware storage, deletion across the pipeline (Parts 5, 10) |
| Accessibility | For an LMS this is a legal requirement, not a nicety (ADA, EN 301 549) | WCAG-conformant experience layer (Part 9) |
| Cost efficiency | Video and idle compute quietly destroy unit economics | FinOps from day one, especially media egress (Parts 3, 10) |
Notice how few of these are “build a feature.” They are properties of the whole system, and they’re the reason an LMS is genuinely hard. They also explain the shape of the series: each later part is, at heart, the disciplined satisfaction of one or two of these NFRs.
The decisive call: modular monolith or microservices?
Now the question every team argues about, usually with more heat than evidence. The bounded-context map looks like a service diagram, and the temptation is to deploy each context as its own microservice from day one. For almost every team building a new LMS, that is a mistake — and an expensive one.
Microservices buy you independent deployability and scaling at the price of a distributed system’s worst tax: network calls where you used to have function calls, distributed transactions where you used to have a database transaction, and an operational burden that a young team cannot carry. Worse is the distributed monolith — services so chatty and coupled that you pay every microservices cost and gain no benefit. Scholr, in a parallel universe where it started with twelve microservices, would have hit its 500-tenant crisis a year earlier and with far less ability to diagnose it.
The pragmatic, senior answer is the modular monolith: one deployable application, but internally partitioned along the bounded contexts, with hard module boundaries enforced in code (no context reaching into another’s internals; communication only through defined interfaces). You get the simplicity of a single deployment and a single database transaction, and you preserve the seams. When a context genuinely needs independent scale — the video pipeline, the real-time tier — you extract it into a service along a boundary you already drew. You earn microservices; you don’t start with them.
| Approach | Operational cost | Transactions | When it’s right |
|---|---|---|---|
| Big-ball-of-mud monolith | Low | Easy | Never (no seams to extract later) |
| Modular monolith | Low | Easy (one DB) | Almost always, to start |
| Microservices | High | Hard (distributed) | Proven scale/team boundaries, extracted gradually |
So Scholr — and our companion build — is a Spring Boot modular monolith over PostgreSQL, with the contexts as enforced modules and a couple of capabilities (media, real-time) destined for extraction when the data demands it.
From contexts to code: the modular monolith in practice
A bounded-context map that lives only in a diagram is a wish. Its value comes from enforcing it in the codebase — and in a Spring Boot modular monolith that enforcement is mechanical rather than aspirational. Each context becomes a top-level module with a deliberately tiny public surface and everything else hidden:
com.scholr.lms
├── identity/ # Identity & Org context
│ ├── api/ # the ONLY package other modules may import
│ ├── domain/ # entities, aggregates, value objects
│ └── internal/ # repositories, services (package-private)
├── catalog/
│ ├── api/
│ └── internal/
├── enrollment/
├── learning/
├── assessment/
└── shared/ # truly shared value objects (e.g. TenantId)
The rule is simple and absolute: a module may import another module’s api package and nothing else — never its repositories, never its entities. You don’t trust good intentions to keep this true; you write an architecture test that runs in CI and fails the build the moment someone crosses a line:
@ArchTest
static final ArchRule contexts_are_isolated =
noClasses().that().resideOutsideOfPackage("..enrollment..")
.should().accessClassesThat()
.resideInAnyPackage("..enrollment.internal..");
Tools like Spring Modulith make this even more first-class, verifying module boundaries and even documenting them automatically. The payoff is the whole reason the modular monolith exists: you get the operational simplicity of one deployable and one database transaction, and boundaries as real as if each context were a separate service — so the day a context genuinely needs independent scale, the seam is already cut. You are building the microservices you haven’t had to pay for yet.
Aggregates, invariants and the consistency you can’t fake
Inside each context, the tactical heart of the design is the aggregate: a cluster of objects treated as one unit for changes, with a single entity as the root and a boundary inside which every business rule — every invariant — must always hold. The aggregate is your consistency boundary. Changes within it are atomic; references to other aggregates are by identity, and they reconcile eventually rather than in the same transaction.
The canonical LMS example is the one that bit Scholr: enrolling a learner into a cohort with limited seats. “Never oversell a cohort” is an invariant, and an invariant is only safe when it’s enforced inside a single aggregate and a single transaction:
// Enrollment context — the Cohort aggregate guards the seat invariant
public class Cohort {
private final CohortId id;
private final int capacity;
private int enrolledCount;
public Enrollment enroll(LearnerId learner) {
if (enrolledCount >= capacity) {
throw new CohortFullException(id); // invariant, enforced here
}
enrolledCount++;
return new Enrollment(id, learner); // one atomic change
}
}
Because the cohort and its seat count live in one aggregate in one database, this is a single transaction — no distributed lock, no race between two services that both believe the last seat is free. That is the quiet superpower of not starting with microservices: the rules that must be exactly right are exactly right, for free. The facts that are allowed to lag — a learner’s aggregate progress, the analytics, the search index — are deliberately pushed across aggregate and context boundaries to be reconciled asynchronously, which is precisely the work of Part 5. Drawing that single line — strong consistency inside the aggregate, eventual consistency across them — is the most consequential modeling decision in the entire system.
Designing the contracts between contexts
If contexts can’t reach into each other’s data, how do they collaborate? Through explicit contracts, and you have two kinds to choose from. The first is a synchronous call against another context’s api — Enrollment asking Catalog, “is this course published?” before granting access. It’s simple and immediately consistent, and inside a monolith it’s just a method call, not a network hop. The second, and increasingly the default for anything that fans out, is the domain event: when something noteworthy happens — LessonCompleted, LearnerEnrolled, CertificateIssued — the owning context publishes a fact, and any context that cares subscribes, without the publisher knowing or caring who is listening.
Events are how you keep contexts decoupled and how eventual consistency actually travels: Progress publishes LessonCompleted; Analytics, Notifications, and the search indexer each react in their own time. In the monolith these can begin as in-process events and graduate, in Part 5, to a durable event backbone with the transactional outbox pattern that guarantees they’re never silently lost. The discipline to start drawing these contracts now — even when every context still lives in one process — is what makes the later extraction of a service a refactor rather than a rewrite. Contracts, not tables, are how a system stays soft enough to change.
The high-level reference architecture
With the domain modeled and the deployment shape decided, we can draw the architecture the rest of the series will fill in. Think of it as a skeleton: today it’s mostly empty boxes, and each subsequent part brings one to life.
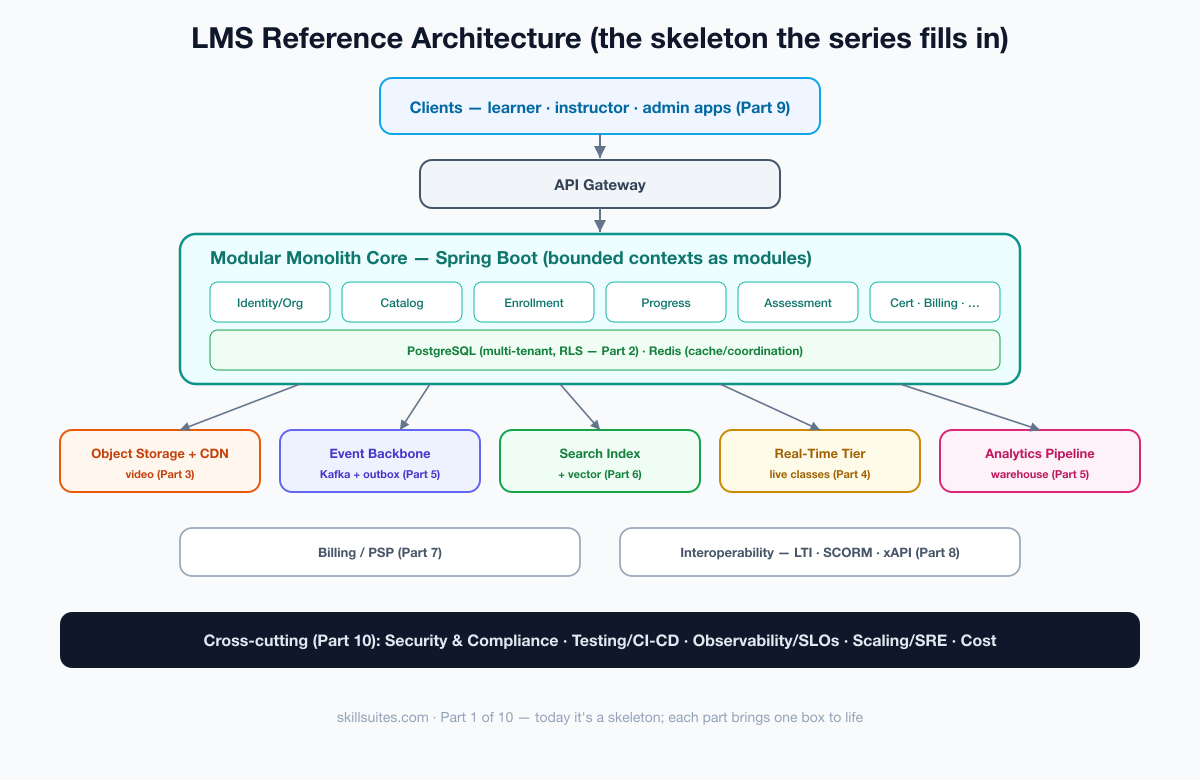
Reading it top to bottom: clients (the learner, instructor, and admin apps from Part 9) reach the system through an API gateway; the modular-monolith core holds the bounded contexts and owns the relational data in PostgreSQL, with Redis for caching and coordination. Off to the sides sit the capabilities that need specialized infrastructure — object storage plus a CDN for video (Part 3), an event backbone that carries every meaningful action (Part 5), a search index kept fresh from that backbone (Part 6), a real-time tier for live classes (Part 4), and an analytics pipeline that turns the event stream into insight. Billing and interoperability (Parts 7 and 8) integrate at the edges. Everything is wrapped, in Part 10, by the cross-cutting concerns — security, observability, and cost — that make it operable.
A word on the technology — and why it comes last
Only now, with the domain modeled and the architecture shaped, does the stack matter — and it should feel almost anticlimactic, because the hard thinking is already done. For this series we build on Spring Boot and PostgreSQL, and the reasons are deliberately boring. Spring Boot is a mature, batteries-included platform for exactly this modular-monolith-to-services journey: strong module support (Spring Modulith), first-class transactions, and an ecosystem for everything from security to messaging. The JVM’s threading and connection-pool model also makes the production failure modes we dissect in Part 10 — thread-pool exhaustion, cascading failure — concrete and teachable rather than hand-wavy. PostgreSQL is the pragmatic default for a multi-tenant SaaS: row-level security for tenant isolation (Part 2), JSON columns when you need flexibility, full-text search to start with, partitioning for scale, and rock-solid transactional guarantees for the invariants that must never break. None of this is exotic, and that is precisely the point — production systems are built from boring, well-understood parts assembled with judgment. The novelty budget belongs in your product, not your plumbing.
Data ownership and consistency boundaries
One more design decision belongs in Part 1 because it constrains everything after: where do you need strong consistency, and where is eventual consistency not just acceptable but necessary? The instinct to make everything immediately consistent is how you build a system that can’t scale.
Some operations demand strong, transactional consistency. Enrolling a learner and decrementing the available seats must be atomic — you cannot oversell a cohort. Recording a payment and granting access must not drift. These live inside a single context and a single database transaction in the monolith, which is one of the quiet superpowers of not starting with microservices.
Other facts can be eventually consistent, and pretending otherwise will wreck your performance. A learner’s aggregate progress across a hundred lessons, the analytics that power instructor dashboards, the search index, the recommendation model — these can lag reality by seconds or minutes without anyone caring, and forcing them to be synchronous would couple everything to everything. The art is drawing the line deliberately: strong consistency inside an aggregate, eventual consistency across contexts, carried by the event backbone we build in Part 5. Scholr’s progress-tracking corruption, it will turn out, came precisely from getting this boundary wrong — writing progress in two places and hoping they agreed.
A pragmatic delivery roadmap
A blueprint this complete can paralyze a team into trying to build all of it at once. Don’t. The roadmap that gets Scholr to a real first release sequences the work so each stage is shippable:
- Foundation first: Identity & Org, Catalog, and Enrollment as modules in the monolith, over a properly multi-tenant database (Part 2). This alone is a usable product for a pilot customer.
- The hard infrastructure next, in order of pain: video delivery (Part 3), then assessments and real-time (Part 4), then the event backbone that everything else depends on (Part 5).
- The growth and discovery layer: search, recommendations, and AI tutoring (Part 6), then the commercial layer of billing (Part 7) and the interoperability that opens the institutional market (Part 8).
- The experience and the hardening: the accessible frontend (Part 9), then the security, testing, scaling, and operations that earn the word “production” (Part 10).
The thread to hold onto: build the modular monolith, keep the seams clean, and extract a service only when a real scaling pressure justifies it. The roadmap is a sequence of shippable increments, not a year-long big bang.
It’s worth being explicit about what Part 1 deliberately leaves unanswered, so the scope is honest. We haven’t chosen a tenancy isolation model, written a line of SQL, or decided how a request authenticates — that is Part 2, because it’s the one-way door that deserves its own treatment. We haven’t touched video, real-time, events, search, billing, interoperability, the frontend, or operations — each is a part of its own. What we have done is the work that makes all of those tractable: named the contexts, drawn the boundaries, fixed the language, chosen the deployment shape, and committed the non-functional requirements that will judge every later decision. That is the highest-leverage day in the whole build, and it is the one most teams skip on their way to a demo they’ll have to rebuild.
What we’d do differently
Honesty is what separates a reference architecture from a sales brochure, so here’s the retrospective even before we build. We’d invest more up front in the ubiquitous language and the context boundaries, because every hour skipped there cost ten later. We’d treat the tenancy model (Part 2) as the one-way door it is and prototype it against a realistic multi-tenant dataset, not three demo orgs. We’d put the event backbone in earlier than feels necessary, because so many features turned out to depend on it. And we’d resist, harder, the seduction of premature microservices — the distributed monolith is the most expensive mistake in this entire domain, and it always begins with good intentions and a clean-looking service diagram.
None of this requires exotic technology. It requires the discipline to design the system before building the demo — which is the whole thesis, and the reason Scholr’s crises are solvable rather than fatal.
Frequently asked questions
Should an LMS start as a monolith or microservices?
A modular monolith, almost always. You get a single deployment and single-database transactions (a huge simplification) while preserving clean module boundaries along your bounded contexts, so you can extract a service later exactly where a real scaling pressure appears. Starting with microservices usually produces a distributed monolith — all of the cost, none of the benefit.
Do I need multi-tenancy from day one?
If you’re building a B2B LMS, yes — retrofitting tenant isolation onto a single-tenant data model is one of the most painful and risky migrations there is. Tenancy is a one-way-door decision; make it deliberately at the start (Part 2 covers the options).
How is modeling an LMS different from a generic CMS?
A CMS manages content; an LMS manages learning — enrollment, progress, assessment, certification, and the relationships between people, cohorts, and content over time, all multi-tenant. The Learning & Progress and Assessment contexts have no CMS equivalent, and they’re where the real complexity lives.
Which compliance regimes apply to an LMS?
Commonly FERPA (US education records), GDPR (EU personal data), and accessibility law (ADA / Section 508 / EN 301 549). They shape data residency, retention and deletion, audit logging, and the experience layer — which is why they appear as first-class NFRs rather than an afterthought.
Conclusion
Scholr’s crises weren’t bad luck; they were the bill coming due for an architecture that was never designed, only grown. In this part we designed it: a precisely modeled domain of bounded contexts, a ubiquitous language, the non-functional requirements that actually drive the build, the decisive choice of a modular monolith, and the reference architecture the rest of the series brings to life. No service mesh, no Kafka — just the senior-engineer judgment that makes those things useful later instead of merely fashionable.
Throughout this series, every architectural decision lands in the companion codebase — a Spring Boot reference implementation that grows one part at a time — so that by the end you don’t merely understand a production LMS, you have a working first version you can run. Part 1’s contribution to that codebase is the foundation everything else stands on: the domain model expressed as enforced modules, and the boundaries that keep the system soft enough to change.
Next, in Part 2, we descend into the foundation everything rests on: the data model and the multi-tenancy strategy — the one-way door, and the place Scholr’s noisy-neighbor problem was hiding all along. If you’re enjoying the systems-design thinking, our production engineering playbook and the system-design case study on RFP evaluation apply the same “design the system, not the demo” discipline to AI.
Where this series goes: Parts 1–10 design and build the production-grade backend. The series then extends into a working, multi-role platform you can run and log into — Part 11 adds real login, role-based access control, and a server-rendered UI, and Parts 12–15 build the instructor, student, and admin workspaces and a rich block-editor authoring system, on top of this exact architecture.
