

Most “AI for proposal evaluation” demos are a single prompt: paste a vendor proposal, ask “is this a good fit for our RFP?”, and trust whatever the model says. That is a toy. Real proposal evaluation is a system-design problem — it needs structure, retrieval of the actual RFP requirements, weighted and deterministic scoring, an audit trail, human sign-off on the borderline cases, and the freedom to run on whatever model your organization is allowed to use. In this 5-part series we will build exactly that: an LLM-agnostic system that evaluates vendor proposals against an RFP, using LangChain and LangGraph, with complete, runnable code.
This first part is pure system design. No code dumps yet — instead, the thinking that separates a senior engineer from a prompt-tinkerer: requirements, constraints, decomposition, trade-offs, and the architecture that falls out of them. Get this right and the implementation (Parts 2–5) becomes almost mechanical.
The knack of a great system design expert
A great system designer does not start with the framework. They start with the problem, the constraints, and the failure modes, and let the architecture emerge:
- Clarify the real requirement — not “use AI”, but “score a proposal against an RFP, defensibly and consistently.”
- Surface the constraints — fairness, auditability, data residency, cost, who is allowed to see the bids.
- Decompose the problem into stages with clear inputs and outputs.
- Identify the hard parts — here, hallucination, explainability, and provider lock-in — and design specifically to tame them.
- Choose technology last, to fit the design.
The product: an LLM-agnostic RFP proposal evaluator
Concretely, we are building a service that ingests a vendor proposal and scores it against an RFP (Request for Proposal) — the set of weighted requirements a buyer publishes. It returns a structured, cited evaluation: which requirements are met, partially met, or not met, an overall weighted fit score, and a sign-off trail for anything borderline.

User stories
- As a procurement lead, I want each incoming proposal scored against our RFP with evidence, so I can shortlist objectively.
- As a bid evaluator, I want borderline proposals to require a human decision before they’re shortlisted or rejected.
- As a CISO, I want to run the whole thing on infrastructure I control, so confidential bids never leave our boundary.
- As an engineer, I want to switch the underlying LLM without rewriting the application.
In scope vs out of scope
| In scope | Out of scope (for this series) |
|---|---|
| Proposal ingestion & highlight extraction | A full e-procurement suite |
| Retrieval of relevant RFP requirements (RAG) | Vendor portal / submission intake |
| Per-requirement assessment with evidence | Multi-language proposals |
| Deterministic weighted fit scoring | A polished web front-end |
| Human-in-the-loop shortlist gate | Contract award workflow |
| Provider-agnostic execution (Azure / Vertex / Ollama) | Fine-tuning custom models |
Requirements: functional and non-functional
Juniors list features. Seniors obsess over the non-functional requirements, because that is where systems live or die — especially where money and fairness are involved.
Functional
- Accept a proposal (Markdown, text, or PDF) and a target RFP.
- Identify the vendor and extract the proposal’s key claims.
- Retrieve the RFP requirements relevant to the proposal.
- Assess each requirement:
met/partially_met/not_met, with evidence. - Compute an overall, explainable, weighted fit score.
- Gate borderline proposals behind a human shortlist decision.
- Produce a cited recommendation: shortlist / reject / review.
Non-functional (the ones that matter most)
| NFR | Why it matters here | Design response |
|---|---|---|
| Auditability | Procurement decisions must be defensible. | Every assessment cites a requirement_id + evidence; the score is deterministic; state is checkpointed. |
| Consistency & fairness | Every bidder must be judged on the same rubric. | The same weighted scoring function runs for all proposals — no model-guessed numbers. |
| Human oversight | Borderline calls need a person on the hook. | A human-in-the-loop gate for scores between the reject and shortlist thresholds. |
| Data residency | Bids are commercially confidential. | LLM-agnostic design, including fully self-hosted Ollama. |
| Cost control | Bulk evaluation can get expensive. | Provider choice + the ability to route to cheaper/local models. |
| Testability | You can’t ship what you can’t test. | Pure scoring functions; stubbed LLM/retriever so the suite runs offline. |
Why this is a graph, not a prompt
The single-prompt approach fails every NFR above: it can’t cite an RFP it never retrieved, it invents a score, it offers no place for a human to intervene, and it has no audit trail. Take the requirements seriously and the problem decomposes into discrete, testable stages — some of which make decisions (is this borderline?) and pause (wait for a human). That is a stateful workflow with conditional branching and persistence — exactly what LangGraph is for.
| Approach | Stateful | Branching | Human-in-the-loop | Auditable | Fit |
|---|---|---|---|---|---|
| Single prompt | No | No | No | No | ❌ Toy |
| LangChain chain (linear) | Limited | No | No | Partial | ⚠ Better, still linear |
| LangGraph (state machine) | Yes | Yes | Native (interrupt) | Yes | ✅ Right tool |
The architecture
A LangGraph workflow at the core, an LLM-agnostic factory layer beneath it, a retrieval layer over RFP “requirement sets,” and thin delivery layers (CLI and HTTP API) on top.
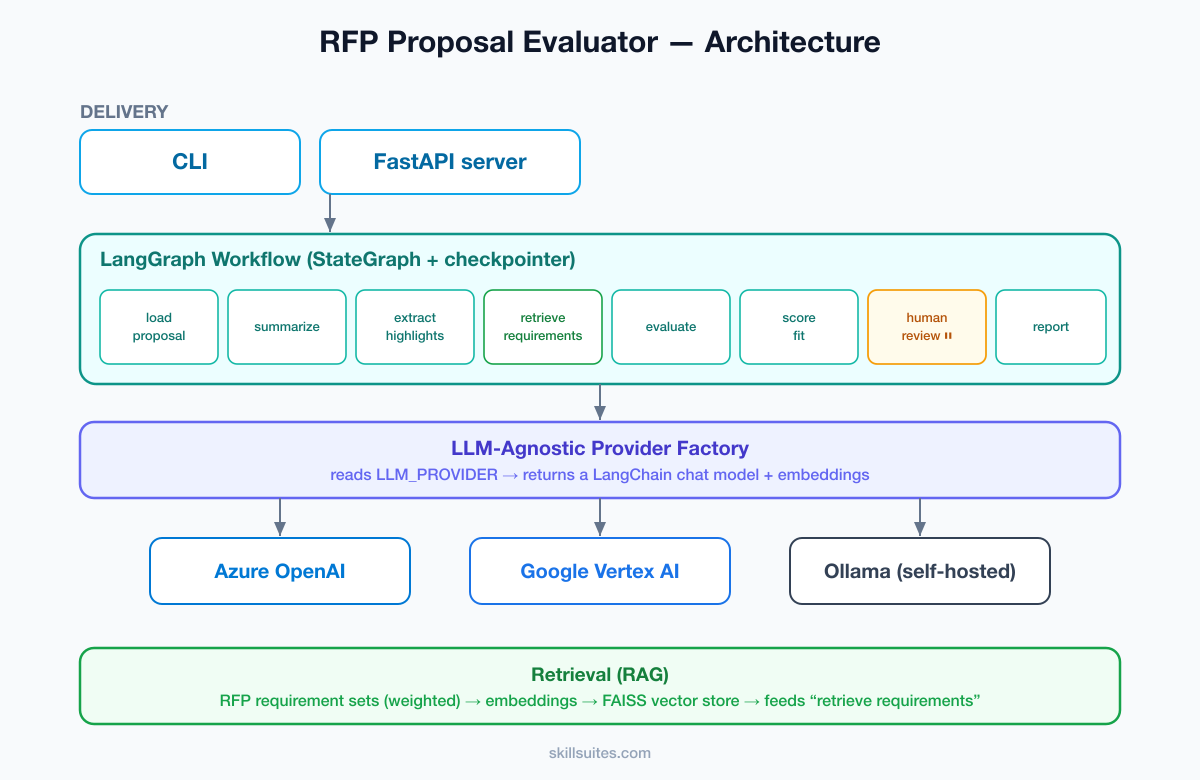
The crucial idea is the provider factory: every model call goes through a single function that reads one setting — LLM_PROVIDER — and returns the right LangChain model. Nodes depend only on the abstract interface; switching from Azure OpenAI to Vertex to a self-hosted Ollama is a one-line change in an .env file. That one decision delivers data residency, cost flexibility, and freedom from lock-in simultaneously.
The evaluation workflow as a graph
The evaluation is a directed graph: linear through ingestion and assessment, then it branches on the fit score. Clear shortlist/reject decisions go straight to the report; borderline scores divert through a human gate that pauses the workflow until a person responds.
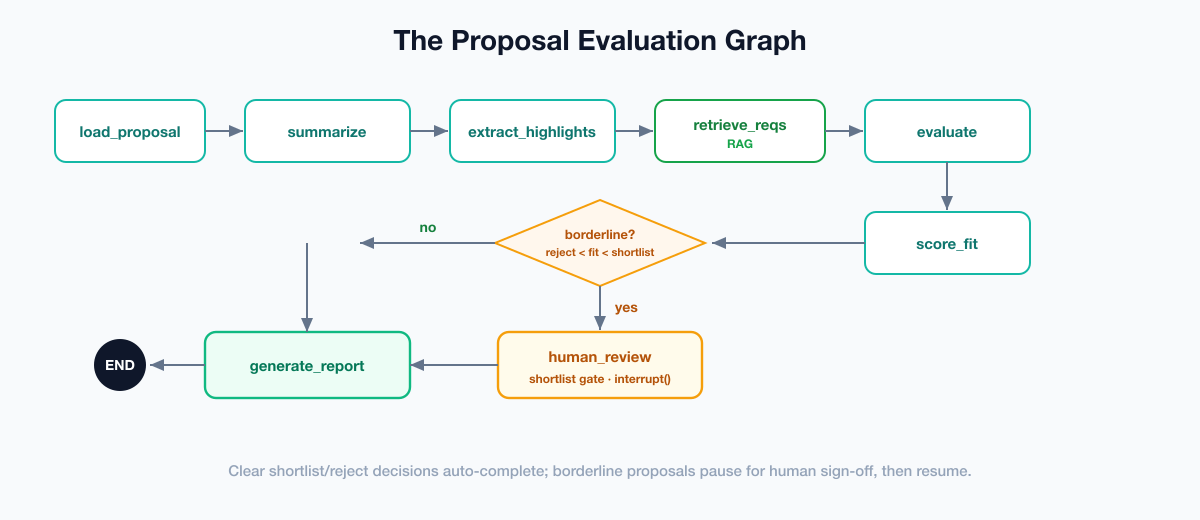
- load_proposal — extract text from Markdown/PDF.
- summarize_proposal — identify the vendor and summarize the offer.
- extract_highlights — pull out the proposal’s key claims and commitments.
- retrieve_requirements — RAG: fetch the RFP requirements relevant to this proposal.
- evaluate_proposal — judge the proposal against each requirement, with evidence.
- score_fit — aggregate into a deterministic 0–100 weighted score.
- human_review — conditional: if the score is borderline,
interrupt()and wait for a human decision. - generate_report — render the cited recommendation.
Designing the weighted fit score (don’t let the LLM pick the number)
A critical design choice: the score must be deterministic, not model-generated. The LLM’s job is the qualitative judgment per requirement (met / partially_met / not_met, with evidence). Each RFP requirement carries a weight; a plain, version-controlled function rolls the judgments into a weighted score (met = full credit, partially_met = half, not_met = none). The result is explainable, reproducible, and fair — every bidder is scored on the identical rubric, and you can point to exactly why. Drawing this boundary — LLM for judgment, code for arithmetic — is the heart of good GenAI system design.
Designing the human-in-the-loop gate
Not every proposal needs a human — that wouldn’t scale — but borderline ones must not be auto-decided. After scoring, a conditional edge compares the score to two thresholds: at or above SHORTLIST_THRESHOLD → shortlist; below REJECT_THRESHOLD → reject; in between → the graph hits interrupt(), checkpoints the state, and hands the findings to a human. They respond shortlist / reject / revise, and the graph resumes exactly where it paused — possibly hours later — because the checkpointer persisted the state.
Cloud vs self-hosted: the trade-off that drives the series
Because the system is provider-agnostic, the model choice becomes a deployment decision. Parts 3–5 each take one path so you can compare them directly:
| Dimension | Azure OpenAI (Part 3) | Google Vertex AI (Part 4) | Ollama on GPU VM (Part 5) |
|---|---|---|---|
| Bids leave your boundary | To Azure (enterprise terms) | To Google Cloud | No — fully self-hosted |
| Setup effort | Low | Low–medium | Higher (manage the GPU VM) |
| Cost model | Per token | Per token | Fixed VM/GPU cost |
| Best for | Enterprises on Azure | GCP-native teams | Air-gapped / max confidentiality |
The point of the agnostic architecture is that you do not have to choose forever: develop against free local Ollama, ship on Azure OpenAI for quality, move a confidential tender fully in-house — all without touching the graph.
The codebase and how the series is organized
All code lives in one repository. The main branch holds the complete app with config-based provider switching; each part has a branch frozen at that lesson’s checkpoint, so you can check out the exact code for any article.
| Branch | Accompanies |
|---|---|
main |
Full app — all providers, switchable via .env |
part-1-product-design |
This article — product & design |
part-2-architecture |
Agnostic architecture & skeleton |
part-3-azure-openai |
Azure OpenAI implementation |
part-4-vertex-ai |
Google Vertex AI implementation |
part-5-ollama-gpu |
Ollama on an Azure GPU VM |
We will run everything with Docker as the primary path (a clean docker compose up that includes a local Ollama), with a virtualenv fallback. That keeps “works on my machine” out of the conversation and mirrors how you would deploy on a VM.
What’s next
In Part 2 we turn this blueprint into a running skeleton: the LLM-agnostic architecture in code — the config and provider factories, the typed state, the graph wiring, the CLI and API, the Docker stack — deployed on an Azure VM, with every moving part explained. Then Parts 3, 4, and 5 plug in Azure OpenAI, Google Vertex AI, and self-hosted Ollama, each end to end with troubleshooting.
Frequently asked questions
What is LangGraph used for in this project?
LangGraph models the proposal evaluation as a stateful graph of nodes with conditional routing, persistence (checkpointing), and native human-in-the-loop via interrupt() — turning a fragile single prompt into an auditable, resumable workflow.
What does “LLM-agnostic” mean here?
Every model call goes through a factory that reads one setting, LLM_PROVIDER, and returns the right LangChain model. You switch between Azure OpenAI, Google Vertex AI, and Ollama by changing an environment variable — no code changes.
How is the fit score kept fair across bidders?
The LLM only decides met / partially_met / not_met per requirement; a deterministic weighted function computes the number. Every proposal is scored on the identical rubric, so the result is consistent and defensible.
Do I need a paid API to follow along?
No. The default configuration uses Ollama, which runs locally and is free. You only need cloud credentials for the Azure (Part 3) and Vertex (Part 4) walkthroughs.
Conclusion
Great GenAI systems are not great prompts — they are well-designed systems that use a model only for the parts models are good at. We started from requirements and constraints, decomposed the problem into a stateful graph, drew clean boundaries (LLM for judgment, code for scoring), and chose an architecture free of provider lock-in. That blueprint is the whole game; the next four parts are implementation. Continue to Part 2: the LLM-agnostic architecture.
This is an independent, educational project built from public documentation and open-source libraries. It is not affiliated with or endorsed by any employer, uses no proprietary code or data, and its output is not procurement or legal advice.
